
Stealing the better parts of Go libraries into Ruby: interval_response
The Go programming language is a curious piece of a kit. Unquestionably successful, no doubt about it - and lots of high-profile Rubyists have taken a liking to it or even moved wholesale (and then espoused vibes to the tune of “I am not using a testing library, look why I am morally superior” and “I run 2 servers instead of your 10, look how much better I am”). Personally, I am not fancying Go that much - primarily because of disagreements with some of the Go authors’ attitudes. I understand their motivation for many design decisions, but take the freedom to disagree and abstain instead of “disagree and commit” as long as getting something done doesn’t require me to work Go specifically. And mind you - there are tasks where Go is undisputably excellent and no better alternative exists. Like making commandline binaries for cross-platform distribution, for instance.
But as much as I have complaints about the built-in language constructs, the condescending existing-but-not-end-user available generics, a (myriad of) byzantine dependency management system(s) and whatnot – let me be very clear on something. The standard library in Go – and many third-party libraries are, by any means, near-stellar. It has a lot of very specific, very useful primitives which, in large, are informed by production concerns which have been encountered by the authors. Timeouts and cancellations, contexts, multi-step HTTP connection setup which allows fine grained control over socket use - brilliant. Even when the anemic language constructs make these libraries screech and wail the library doesn’t become less great - and from a Ruby perspective we are spoiled by having a pretty rich standard library to begin with.
One of the great things (maimed by backwards compatibility, and yet) in Go is the ZIP library - archive/zip which served as one of the inspirations for zip_tricks in terms of functionality and the API. It certainly did find some use during the making of the Google download servers, as described in bradfitz’ presentation and the approach was very influential for us when making ours.
Another bit of excellent standard library mojo which comes from this download server experience at Google is the oddly named serveContent function from the net/http package - which hides a few great devices under the hood, the disguises of its modest signature. The function is quite neat in that it implements random access to an arbitrary resource (anything that implements io.ReadSeeker) and allows this random access to be excercised by the client using the Range: HTTP header. The function even is able to serve multipart responses - something S3 doesn’t even support. So quite some sophistication down there. Although it has its own share of problems, which follows Julik’s Law Of Private Final Sealed Concrete API separation principle:
If the author of a library is forced to mark things as inaccessible to change or overrides, exactly the parts which need changing or overriding the most will get marked inaccessible - see also)
Now, Brad’s presentation includes another interesting bit of information. which is that you can assemble a virtual IO object (what this io.ReadSeeker actually is - it is an amalgamation of the Read() and Seek() methods) which represents multiple files (or objects on a remote storage system - such as S3) by stringing those objects into a single, linear IO. Kind of like so (for our ZIP situation):

This allows us to create a “virtual” HTTP resource with random access even though this resource is, under the hood, stitched together from multiple parts which are never stored together in one place. Brad achieves it using an object called a MultiReaderAt or a MultiReadSeeker. This is the part where I cheat - even though it was proposed to add it to the Go stdlib one has to look at the implementation made available as part of Perkeep. But it still can be found in the linked docs.
This multi-reader-seeker-closer-atter (this Go interfact composition thing is beautiful when there are no generics, right?) internally uses one of my favourite algorithms - binary search. It gets used to quickly find the right segment. Imagine you have the following list of segments that you want to “splice” together:
ZIP header (64 bytes)
S3 object (1297 bytes)
ZIP header (58 bytes)
S3 object (48569 bytes)
ZIP central directory (886 bytes)
Imagine we get a request for the following Range: - bytes 1205-13605. We would need to first read bytes 1141-1296 from our second segment, then bytes 0-57 from our third segment, and finally bytes 0-12186 from our fourth segment to fulfill that request. This is where the binary search comes in! Imagine we store our segments as tuples of {size, offset}. Then we would have a list of tuples of this shape:
{size=64, offset=0}
{size=1297, offset=64}
{size=58, offset=1361}
{size=48569, offset=1419}
{size=886, offset=49988}
We could scan the list from the beginning, looking for the offset value which is at or below our requested range start, and then do another scan (or continue our initial scan) until we find the tuple which covers the end of our range. Then we do a bit of arithmetic to get the range “within” the segment, by doing requestedRangeStart - segment.offset and requestedRangeEnd - segment.offset and let the segment “read” itself. Or read it externally. For example, dropping back to Ruby
segment.seek(range_in_segment_start, IO::SEEK_SET)
segment.read(range_in_segment_end - range_in_segment_start + 1)
But if we have a very, very long list of ranges? Imagine a ZIP file with 65 thousand files, that makes it a segmented response composed of no less than 130001 segments, if you remember your ZIP file format structure. If we only need to return one range, then we’ll have to do 1 scan, worst case passing 130000 entries. This can get pretty expensive pretty quickly, and will need even more optimization if multiple ranges are requested (and we do want to support that use case). This gives us linear - O(n) performance, where n is the number of segments.
This is where binary search comes in (and of course, it is used in the MultiReadSeeker too, by applying the sort.Search function): since the segments are sorted by their offset we can reduce the complexity to O(log n) by splitting the search list in half each time we drill down. The best illustration of the binary search algorithm from Wikipedia:

Ruby Arrays have a built-in method called #bsearch, which, by default, uses the same semantics as the “boat operator” (<=>) - normally used for sorting. The standard setup of bsearch implies that you can return the result of <=> from the block and this is sufficient for an exact match (0 means “found”).
Since we are looking for an inexact match we will have to alter the search block like so:
@intervals.bsearch do |interval|
# bsearch expects a 0 return value for "exact match".
# -1 tells it "look to my left" and 1 "look to my right",
# which is the output of the <=> operator. If we only needed
# to find the exact offset in a sorted list just <=> would be
# fine, but since we are looking for offsets within intervals
# we will expand the "match" case with "falls within interval".
if offset >= interval.offset && offset < (interval.offset + interval.size)
0
else
offset <=> interval.offset
end
end
Note that a peculiar property of the boat operator is that it is not commutative because it is a message on the receiver rather than a function (in this instance, the <=> implementation on offset, that is - on an Interger - decides the outcome of the comparison).
This allows us to use our “intervals IO” for various purposes - for example, feeding a segmented file to our own format_parser and have it be accessed as a single entity. The code below covers the entire subset of IO that FormatParser requires:
class RopeIO
def initialize(*ios)
@seq = Segments.new(*ios)
@pos = 0
end
def seek(absolute_offset)
@pos = absolute_offset
end
def size
@seq.size
end
def read(n_bytes)
buf = String.new(capacity: n_bytes)
read_range = @pos..(@pos + n_bytes - 1)
@seq.each_in_range(read_range) do |io, range_in_block|
io.seek(range_in_block.begin, IO::SEEK_SET)
buf << io.read(range_in_block.end - range_in_block.begin + 1)
end
@pos += buf.bytesize
buf.bytesize == 0 ? nil : buf
end
end
By the way, a different surprising use of this pattern is constructing a non-linear editor timeline, for both video and audio. Observe:
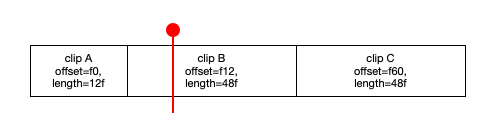
If you are thinking DAW then replace the frame numbers/counts with sample numbers/counts. In this situation, the most efficient way of finding the frame under the playhead will be using the same approach (use binary search to find the segment underneath the playhead, then add the local offset of the playhead within the clip to the “edit in” point of that clip, in this case it is Clip B).
Once we have our “splicing IO” bit covered, we can expand our abstraction “upwards”. Where Go has its http.ResponseWriter object we have our Rack specification and its iterable bodies, and we have the Rack utility methods (the aptly named Rack::Utils module) for parsing our Range: headers. This is where the Go implementation of serveContent() shows how privatizing parts of the API willy nilly creates a bad user experience: there is no way to take and use just the parser of the Range: header. In Rack it is readily available plus there was less incentive to privatise it, meaning that it is a stable API we can rely on. As long as we follow Rack’s semantic versioning guarantees at least. So:
range_serving_app = ->(env) {
ranges_in_io = Rack::Utils.get_byte_ranges(env['HTTP_RANGE'], interval_sequence.size)
...
}
Of course, we also need to furnish some kind of a readable body - an object that responds to each and yields Strings into the passed block. My former colleague Wander recently wrote a neat article about streaming in Rack and you might want to have a look at it for a refresher. Since we have our segment_sequence object available, and this object supports range queries, we can construct an object which will “dig” into our IOs and return the data from the requisite ranges:
class RangeResponseBody < Struct.new(:segment_sequence, :http_range)
def each
segment_sequence.each_in_range(http_range) do |io_for_segment, range_in_io|
# To save memory we will read from the segment in chunks
bytes_to_read = range_in_io.end - range_in_io.begin + 1
chunk_size = 65 * 1024
whole_chunks, remainder = bytes_to_read.divmod(chunk_size)
io_for_segment.seek(range_in_io.begin, IO::SEEK_SET)
whole_chunks.times do
yield(io_for_segment.read(chunk_size))
end
yield(io_for_segment.read(remainder)) if remainder > 0
end
end
end
and we then wire it into our Rack application, roughly like so:
range_serving_app = ->(env) {
interval_sequence = ...
ranges_in_io = Rack::Utils.get_byte_ranges(env['HTTP_RANGE'], interval_sequence.size)
iterable_body = RangeResponseBody.new(interval_sequence, ranges_in_io.first)
[206, {}, iterable_body]
}
Of course there is also some bookkeeping to do so that we return the correct Content-Range header, so that the ETag reflects the composition of the segments and the like. And, before long, we have carried over most of the serveContent + MultiReadSeeker goodness from Go. And it now lives happily inside our download server. Needless to say, you can also use it - find it on Github
So - serveContent is a really neat invention, and porting it was a great and fun excercise. For one - it reaffirmed my belief in the value of open polymorphism. There is no casting anywhere - anything you want to compose into an IntervalSequence will be given back to you once you start iterating over objects, and it is possible to actually use something else than IOs entirely, making it more useful - see above for the video clips on a timeline example.
Also, it presented a great use case for “sum types”. Although Ruby is no Haskell, nothing cancels the fact that we can return an object which conforms to a certain interface, and that interface is one and the same - yet we can return different values for each type of response that we want. In interval_response we have 5, with Multi, Single, Full, Empty and Invalid being the variants, which all get used the same. Of these, Multi is probably the most involved. As Sandy Metz suggests, we do inheritance here - but not for the sake of typechecking, but so that there is a piece of code that outputs a sensible piece of documentation with regards to the “baseline” methods such an interval response must support. And the inheritance hierarchy is “wide and shallow”.
And finally, it gave me the opportunity to “cut” between the private and public API sections much more rigorously and with less disadvantages for a user, as smaller blocks compose better and are also much more pleasant to test.
Splendid. Great ideas port well.