
The unreasonable effectiveness of leaky buckets (and how to make one)
One of the joys of approaching the same problem multiple times is narrowing down on a number of solutions to specific problems which damn work. One of those are idempotency keys - the other are, undoubtedly, rate limiters based on the leaky bucket algorithm. That one algorithm truly blew my mind the first time Wander implemented it back at WeTransfer.
Normally when people start out with rate limiting, a naive implementation would look like this:
WebRequest.create!(at_time: Time.now)
if WebRequest.where(key: request_ip).where("at_time BETWEEN ? AND ?", 1.minute.ago, Time.now).count > rate_limit
raise "Throttled"
else
WebRequest.create!(key: request_ip, at_time: Time.now)
end
This has a number of downsides. For one, it creates an incredible number of database rows - and if you are under a DOS attack it can easily tank your database’ performance this way. Second - there is a time gap between the COUNT query and the INSERT of the current request. If your attacker is aggressive enough, they can overflow your capacity between these two calls. And finally - after your throttling window lapses - you need to delete all those rows, since you sure don’t want to keep storing them forever!
The next step in this type of implementation is usually “rollups”, with their size depending on the throttling window. The idea of the rollups is to store a counter for all requests that occurred within a specific time interval, and then to calculate over the intervals included in the window. For example, with requests during 5 seconds, we could have a counter with a secondly granularity:
if WebRequest.where(key: request_ip).where("second_window BETWEEN ? AND ?", 5.seconds.ago.to_i, Time.now.to_i).sum(:reqs) > rate_limit
raise "Throttled"
else
WebRequest.find_or_create_by(key: request_ip, second_window: Time.now.to_i).increment(:reqs)
end
This also has its downsides. For one, you need to have good granularity counters, meaning that the interval which you count (be it 1 second, 1 day or 1 hour) need to be cohesive with your throttling limit. You can of course choose to use intervals sized to your throttling window and sum up “current and previous”, but even in that case you will need 2 of those:
|••••••• 5s ••T-----|----- 5s -----T•••|
There is also an issue with precision. If you look at the above figure, “window counters” would indicate that your rate limit has been consumed even though looking back 5 seconds from now you are not covering the entire 5 second window looking back, but just a portion of it. So if you sum the counter for the current interval and the last, the sum might be higher than the actual resource use for the last 5 seconds.
As a matter of fact, this is what early version of prorate did.
🧭 I am currently available for contract work. Hire me to help make your Rails app better!
Bring me the bucket!
A leaky bucket solves all of these issues, and the best is - you need only one record per bucket. Let’s recap how it works. A leaky bucket is a function over time - something we as web developers do not encounter very often, but it will be familiar to anyone who coded games or simulations. It is something like water in a pipe or charge of a capacitor modeled over time. Let’s plot a leaky bucket with a capacity of 3 and a leak rate of 1.5 per second:
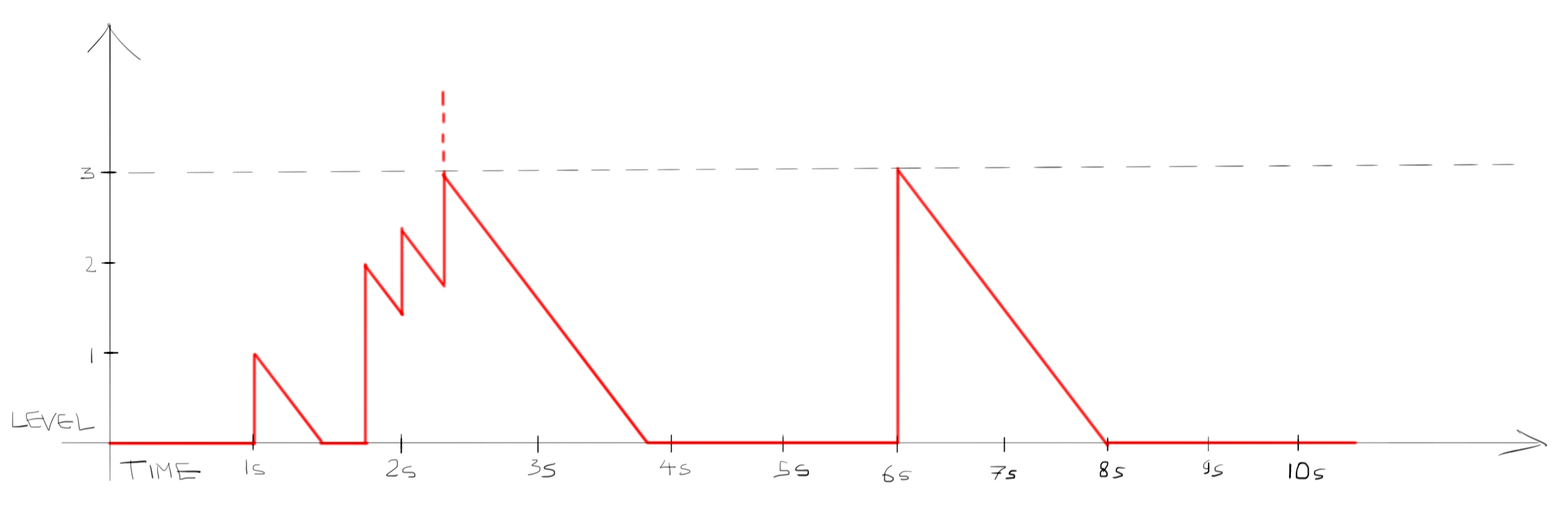
The bucket starts from the empty state (level of 0) and continues in that empty state until 1 second. At 1 second the bucket gets filled up with 1 unit of work. The level of the bucket then decays linearly at the constant rate of 1.5/s until it reaches zero again. Note that it does not go negative. At 1.7s 2 units of work get added, and the level shoots up to 2, and then decays again at the same linear rate. At 2s another 1 unit of work gets added, and again the level shoots up but then starts to decay. Then at 2.3s again 2 units of work get added. Now the level overshoots the 3 - which is the capacity of the bucket, denoted by the dashed line. The capacity of the bucket is limited at 3, so we do not allow the bucket to overfill - instead, we register the spillover as an event of the bucket filling up, which we can register instantly (indicated by the dashed red line). At this stage we allow the bucket level to decay linearly again, but we can use the known fact that the bucket did overflow when we filled it up to generate side effects - for example, for blocking further requests/units of work. Then the bucket level decays back to 0, and at 6 seconds 3 units of work get put in - which again fills the bucket up, which generates another “bucket filled up” event.
When we want to represent it digitally, it is enough to keep track of one value - the level of the bucket - and we could of course do it over discrete increments (like a millisecond, or a microsecond). But the decay of the bucket is very easy to interpolate, which gives us an easy way to represent this state by recalculating the level at the moments when the bucket gets filled up with units of work. As long as we know what the last known level was and at what time, we can calculate the current level by subtracting the leak rate multiplied by the time delta from last level measurement. Consequently, we only need to store two pieces of data for the entire bucket: the last measured level and the time at which the level got measured.
Tracking buckets economically
Formally, such a leaky bucket can best be modeled as a continuous time function because knowing the “fillups” of the bucket (amount and occurrence time) is enough to calculate the level of the bucket in-between those occurrences, with arbitrary precision (as long as our calculation comes after a known sample). So, now the interesting part: how do we actually code this model?
Imagine we have a bucket which fits a certain capacity of capacity. This bucket may contain capacity - and no more - of content. There is a hole in the bucket, which leaks leak_rate contents over 1 unit of time (say – a second). When a request comes in, we put 1 unit of contents into the bucket:
level = level + 1
We then calculate how much has leaked out of the bucket since we last looked at the bucket state, and we store the time when we addressed this particular leaky bucket:
delta_t = now - atime
level = level - (leak_rate * delta_t)
atime = now
Then we clamp our bucket to the allotted capacity - to know whether we just filled it up or not:
level = clamp(0, level, capacity)
We can then determine what actions to take based on the reached value of level:
bucket_full = level == capacity
For example, we can set an arbitrary capacity and block the client until the bucket leaks back to its empty state:
time_to_empty = level / leak_rate
[429, {"Retry-After" => time_to_empty.ceil.to_s}, []]
Or we might want to block the client for an arbitrary amount of time instead:
time_to_empty = 30
[429, {"Retry-After" => time_to_empty.to_s}, []]
No need to simulate an entire system – just one cell is enough
We can model the leaky buckets as a discrete time function, which is what Brandur was describing in his article here, where we would need to “drip” out the buckets at fixed time intervals, like so:
Thread.new do
loop do
sleep 0.1
$leaky_buckets.each do |bucket|
bucket.leak_according_to_delta
end
end
end
Indeed, this setup has a very big downside - the trick though is that it is absolutely unnecessary! It is enough to “drip out” a bucket when we access it, and only that particular bucket - not the others. In fact this is the beauty of Wander’s implementation in Prorate which has impressed me so much!
And make no mistake - maybe this very article lists some “downside” to something which turns out not to be true. Trust, but verify.
You don’t have to only fillup by 1
Crucially, while the description of leaky bucket algorithms implies that the bucket contains “tokens” - which would be things like TCP packets - all we need for a working implementation is an amount expressed as a floating point number. This means that we can use the leaky buckets for much nicer things than throttling an HTTP request. Specifically, that n that we “top up” the bucket with can actually be any value, a representation of cost. For example, imagine you have a system where a user may create a very large number of records in your database by performing batch requests. The user can send any number of articles, in a payload like so:
[
{"id": "713bd518-1bc1-468c-a1a3-7e940b2fba01", "title": "How to get promoted"}, url: "https://www.spakhm.com/p/how-to-get-promoted"},
{"id": "7f63d791-3d05-4529-9bbe-4a1fca510a9e", "title": "People can read their manager's mind", url: "https://yosefk.com/blog/people-can-read-their-managers-mind.html"},
...
]
You know that more than 10000 INSERTed rows will tank the performance of your database. But you also know that allowing large lists of articles to be inserted at once is an essential function of your software, and you can’t really limit the requests to create no more than, say, 10 articles at a time. You also do not want to consider all requests equal - a request creating 1 article “costs” you less than a request which creates 1000 articles. With a leaky bucket we can actually transform the amount of INSERTs the request will do into the cost of a request, and use that instead of incrementing by 1:
articles = JSON.parse(request_body)
n_rows = articles.length
level = clamp(0, level - (leak_rate * delta_t) + n_rows, capacity)
if level == capacity
return [429, {"Retry-After" => time_to_empty.to_s}, ["Too many entries at once"]]
end
By the same token you could assign a “cost” to an operation on your system and throttle on that.
Enough babble, let’s build one for ourselves.
A leaky bucket limiter is very straightforward, the only tricky bits are atomicity and how to make this atomicity function in combination with various data storage models. Let’s start with the simplest one: we will have an in-memory leaky bucket which only exists as long as the object owning it exists.
class LeakyBucket
class State
attr_reader :level
def initialize(level, is_full)
@level = level
@full = is_full
end
def full?
@full
end
end
def initialize(leak_rate:, capacity:)
@atime = Process.clock_gettime(Process::CLOCK_MONOTONIC)
@level = 0.0
@leak_rate = leak_rate.to_f
@capacity = capacity.to_f
end
def fillup(n)
now = Process.clock_gettime(Process::CLOCK_MONOTONIC)
@level = [0.0, @level - ((now - @atime) * @leak_rate)].max
@level = [@level + n, @capacity].min
@atime = now
State.new(@level, @level.round == @capacity.round)
end
end
You might wonder why we put leak_rate and capacity in the constructor – this will become clear in a minute. Let’s use our freshly obtained leaky bucket powers:
[77] pry(main)> b = LeakyBucket.new(leak_rate: 1, capacity: 10) # Allow 10 requests in 10 seconds
=> #<LeakyBucket:0x0000000110838978 @atime=3165329.044493, @capacity=10.0, @leak_rate=1.0, @level=0.0>
[78] pry(main)> b.fillup(2)
=> #<LeakyBucket::State:0x0000000102a62360 @full=false, @level=2.0>
[79] pry(main)> b.fillup(2)
=> #<LeakyBucket::State:0x0000000106706a00 @full=false, @level=2.776740999892354>
[80] pry(main)> b.fillup(2)
=> #<LeakyBucket::State:0x0000000106795cf0 @full=false, @level=3.899269000161439>
Note that we do not add a full? method to the LeakyBucket itself. Why is that? Well, if we look at our level plot figure, we will see that we can only register that the bucket reached it’s capacity momentarily, exactly at the moment of fillup. Using our model we can measure the level accurately after the capacity was hit, but by that time some level would have leaked out already! So while we can add a level method to the bucket, it will never actually indicate that the bucket is full (barring some time resolution gymnastics of the CPU and memory and whatnot). So this is certainly possible:
b.fillup(4) #=> Reaches capacity
b.full? #=> Likely to return false even though we reached capacity right before
💡 We must return a
Statestruct and use that for our check whether we filled up the bucket. That is because the bucket is only full for an instant.
Also note that I round the level and capacity before comparing them - such is the tradeoff of using floats for the leaky bucket level. You could use the same model with rounded-off level, at which point your bucket would become “a bucket of tokens”.
It doesn’t seem like much - we have an in-memory state and if we are using it inside a web request we won’t be able to get a lot of use out of it. But even in this minimal form this leaky bucket can be used inside of a background job:
b = LeakyBucket.new(leak_rate: 10, capacity: 30) # 300 requests during 30 seconds
loop do
if b.fillup(1).full?
sleep 1 # Allow some time to release
next
end
remote_api_client.request("/payments", params)
end
We can control a request rate to an API and sleep if the requests are coming in too often.
Adding rudimentary flow control
Another interesting use of a leaky bucket is monitoring spending. Imagine you are allowed to spend no more than 1000.- AMUs (Arbitrary Money Units) on some type of expense within 30 days, since that is your budget - this is a need that could easily arise in a fintech for example. You could say that:
spend_limit = LeakyBucket.new(leak_rate: (1000.0 / 30 / 24 / 60 / 60), capacity: 1000)
spend_limit.fillup(30) # Spent 30.- AMUs on groceries
spend_limit.fillup(990).full? # Overspent!
In our example we do see that there is a feature one would likely want to have though. Imagine we want to determine whether we are permitted to spend a certain amount of money, and forbid that spend if it would be too large? If we use fillup, we would change the state of the bucket - while other transactions would need to go through unscathed, yet we already filled the bucket to the brim. For rate limiting this might be an acceptable shortcoming, but for spend this might be undesirable. It can be very useful to have a simple question method for this instead:
def able_to_accept?(n)
now = Process.clock_gettime(Process::CLOCK_MONOTONIC)
level_after_leak = [0.0, @level - ((now - @atime) * @leak_rate)].max
level_after_leak + n > @capacity
end
Now, if our withdrawal would be too large, we can deny it and allow smaller withdrawals to go through:
spend_limit = LeakyBucket.new(leak_rate: (1000.0 / 30 / 24 / 60 / 60), capacity: 1000)
if spend_limit.able_to_accept?(30)
spend_limit.fillup(30) # Spend 30.- AMUs on groceries
end
if spend_limit.able_to_accept?(990)
spend_limit.fillup(990) # Only spend what we are allowed to
end
💡 Note that this type of function often gets called
peek, which is a very obscure name. The only positive of it is some chance of cognitive familiarity through tradition, yet that tradition largely belongs to mostly-retired people with a standing shortage of characters. I implore you to not call your functionspeekunless they have to do with IO or parsers. Pretty pretty please!
Sharing a leaky bucket between requests
A leaky bucket which can only be used within one unit of work (a job or a web request) is not much to write home about - rate limiting truly comes into its own when used across requests. This is fairly easy to do, as long as we remember that our webserver (like Puma) will be multithreaded, so the accesses to a particular bucket should be mutexed-protected. We will need a mutex for the shared leaky buckets table, and a mutex for every bucket we use. Thanks to the magic of OOP we can compose our existing LeakyBucket implementation into our expanded solution:
$leaky_buckets = {}
$leaky_buckets_mutex = Mutex.new
class SharedLeakyBucket
def self.new(name, **options_for_leaky_bucket)
$leaky_buckets_mutex.synchronize do
$leaky_buckets[name] ||= super(**options_for_leaky_bucket)
end
end
def initialize(**options_for_leaky_bucket)
@leaky_bucket = LeakyBucket.new(**options_for_leaky_bucket)
@mutex = Mutex.new
end
def fillup(n)
@mutex.synchronize { @leaky_bucket.fillup(n) }
end
end
This gives us a shared table of leaky buckets which is protected by a mutex, and that “singleton” mutex is only locked when we create or lookup our named bucket. The table is going to be keyed by the bucket name.
Now we can use our leaky bucket from multiple requests, as long as it has a descriptive name - such as the IP address that is accessing our service:
rack_app = ->(env) {
req = Rack::Request.new(env)
b = SharedLeakyBucket.new("throttle-#{req.ip}", leak_rate: 10, capacity: 300)
if if b.fillup(1).full?
[429, {"Retry-After" => "30"}, []]
else
# ... do web stuffs
end
}
If your requirements do not need sharing the leaky bucket between processes - say, you are running a small service from just one Puma process or using falcon - and you are fine with the leaky buckets getting lost when the server is restarted - this can be fairly usable. Let’s not forget to clear out the old buckets from time to time:
$leaky_buckets_mutex.synchronize do
$leaky_buckets.delete_if { |_, bucket| bucket.fillup(0).level < 0.0001 }
end
For example you can do this on every Nth call to SharedLeakyBucket.new
Placing the bucket in a database
While a database is not necessarily the best data store for leaky buckets because of very frequent writes it does offer us some advantages because of its intrinsic properties:
- It is atomic, so no need for mutexes
- It can be shared between multiple processes and multiple servers
Let’s implement our leaky bucket in terms of PostgreSQL. First, we create a table:
CREATE TABLE leaky_buckets (
name VARCHAR(255) NOT NULL,
level FLOAT DEFAULT 0.0,
atime TIMESTAMP,
expires_at TIMESTAMP
);
CREATE UNIQUE INDEX name_idx ON leaky_buckets (name);
CREATE INDEX exp_idx ON leaky_buckets (expires_at);
Then we need to reformat our fillup function to perform a SQL “upsert”, returning the newly reached level. Note that all the calculations are done in SQL so that the changes to the level are atomic and we do not end up with compare-and-set data races, this is what makes the SQL statement longer than one would expect:
def fillup(n_tokens)
conn = ActiveRecord::Base.connection
# Take double the time it takes the bucket to empty under normal circumstances
# until the bucket may be deleted.
may_be_deleted_after_seconds = (@capacity.to_f / @leak_rate.to_f) * 2.0
# Create the leaky bucket if it does not exist, and update
# to the new level, taking the leak rate into account - if the bucket exists.
query_params = {
name: @key,
capa: @capacity.to_f,
delete_after_s: may_be_deleted_after_seconds,
leak_rate: @leak_rate.to_f,
fillup: n_tokens.to_f
}
sql = ActiveRecord::Base.sanitize_sql_array([<<~SQL, query_params])
INSERT INTO leaky_buckets AS t
(name, atime, expires_at, level)
VALUES
(
:name,
clock_timestamp(),
clock_timestamp() + ':delete_after_s second'::interval,
LEAST(:capa, :fillup)
)
ON CONFLICT (key) DO UPDATE SET
atime = EXCLUDED.atime,
expires_at = EXCLUDED.may_be_deleted_after,
level = GREATEST(
0.0, LEAST(
:capa,
t.level + :fillup - (EXTRACT(EPOCH FROM (EXCLUDED.atime - t.atime)) * :leak_rate)
)
)
RETURNING level
SQL
# Note the use of .uncached here. The AR query cache will actually see our
# query as a repeat (since we use "select_value" for the RETURNING bit) and will not call into Postgres
# correctly, thus the clock_timestamp() value would be frozen between calls. We don't want that here.
# See https://stackoverflow.com/questions/73184531/why-would-postgres-clock-timestamp-freeze-inside-a-rails-unit-test
level_after_fillup = conn.uncached { conn.select_value(sql) }
State.new(level_after_fillup, (@capacity - level_after_fillup).abs < 0.01).tap do
# Prune buckets which are no longer used. No "uncached" needed here since we are using "execute"
conn.execute("DELETE FROM leaky_buckets WHERE expires_at < clock_timestamp()")
end
end
and similar for able_to_accept? like so:
def able_to_accept?(n)
conn = ActiveRecord::Base.connection
query_params = {
name: @name,
capa: @capacity.to_f,
leak_rate: @leak_rate.to_f
}
# The `level` of the bucket is what got stored at `atime` time, and we can
# extrapolate from it to see how many tokens have leaked out since `atime` -
# we don't need to UPDATE the value in the bucket here
sql = ActiveRecord::Base.sanitize_sql_array([<<~SQL, query_params])
SELECT
GREATEST(
0.0, LEAST(
:capa,
t.level - (EXTRACT(EPOCH FROM (clock_timestamp() - t.atime)) * :leak_rate)
)
)
FROM
rate_limiter_leaky_buckets AS t
WHERE
name = :name
SQL
# If the return value of the query is a NULL it means no such bucket exists, so we assume the bucket is empty
current_level = conn.uncached { conn.select_value(sql) }.to_f
current_level + n > @capacity
end
Note that we are adding an index and deleting expired buckets to keep our table to a reasonable size.
Placing the bucket in Redis
This will be long-winded, so really - just use prorate. Wander has described the basics of Lua scripting in Redis which makes Prorate tick in his article and the Lua code from Prorate can easily be loaded into Redis from something else than Ruby. Wander even built a small Prorate clone in Crystal. Alternatively, if you are using Sidekiq Pro I’ve heard that it includes a leaky bucket rate limiter as well.
In closing
There is of course more to explore with leaky buckets. For example one could add reservations and all that, but this would make the post even longer than it already is. Let’s just finish off by saying that leaky buckets are great (and cheap), you can and possibly should add them to your application, and hopefully this article gives you a good general idea how to implement one.