
Actually creating a gem for idempotency keys
I’ve already touched on it a bit in the article about doing the scariest thing first – one of the things we managed to do at WeTransfer before I left was implementing proper idempotency keys for our storage management system (called Storm). The resulting gem is called idempo and you use it about like this:
config.middleware.insert_after Rack::Head, Idempo, backend: Idempo::RedisBackend.new(Redis.new)
It is great and you should try it out. If you are pressed for time, TL;DR: we built a gem for idempotency keys in Rack applications. It was way harder than we expected, and we could not find an existing one. As a community we do not publish enough details about how software gets designed, which makes it less likely that our software will be found and used. I don’t want this to happen to idempo. Making a gem which does a seemingly tiny thing can be devilishly complex, and switchable implementations for things are actually useful.
Disclaimer: consider all code here to be pseudocode. For actual working versions of the same check out the code in idempo itself.
Why did we even need it?
To recap: idempotency keys allow you to reject double requests to modify the same resource (or to apply the same modification to the same resource), and they map pretty nicely both to REST HTTP endpoints and to RPC endpoints. Normally idempotency keys are implemented using a header. For a good exposition on idempotency keys, check out the two articles by Brandur Leach here - the first one gives a nice introduction, and the second one gives a much more actionable set of guidelines for implementing one.
The point where we realised that we will need idempotency keys in the first place came about when we decided to let other teams use a JavaScript module that we would provide. The module - and the upload protocol WeTransfer uses - is peculiar in that it has quite a bit of implicit state. Multiple requests are necessary, and they need to be synchronised somewhat carefully. Requests should be retried, because we were already using a lot of autoscaling - so a server could end up dying during a request. Yet some of the operations we let our JS client perform (such as creating a new transfer) must be atomic - you can only create a transfer once, and there is some bookkeeping involved when doing that. The transfer is going to have a pre-assigned ID, and if the client attempts to create a transfer and then does not register properly that the transfer got created the ID will end up taken. This bookkeeping touches the database, and thus creates database load. Also, the output of those operations can be cached for some time. In the past, we had situations where an uploader would end up in an endless loop (due to problems with retry logic for example) and would hit the same endpoint, near-endlessly, and very frequently. If we had an idempotency key system we could significantly reduce the impact this had on our systems – and avoid a number of production incidents. So with the new JS client we wanted to make it support an idempotency key for the entire upload process for your transfer, and we wanted to have this idempotency key be transparently used on the server.
As a matter of fact, also our iOS app ended up implementing idempotency keys in the same way - and with the same benefits.
Surprisingly to us, while Ilja Eftimov has made a good write up about idempotency keys and made a demo of an implementation in this article we were surprised to find no proper gems for idempotency keys existed, which we could pick off the shelf. So some brainstorming and a little pondering later we decided that we had to make one, albeit only for our storage manager system. It is not that Ilja’s code is bad – it just omits a few interesting side-effects which might be more frequent than we could think of initially.
This article is long, and there are a few things I want to touch on here.
Before we move any further: idempo came about with great help from Lorenzo Grandi and Pablo Crivella, sending my hugs to both. Lorenzo is also in the fabulous new Honeypot documentary that you can find here.
🧭 I am currently available for contract work. Hire me to help make your Rails app better!
- It takes quite a bit of work not only to build, but to design a library. I want to cover the design part here in more detail, because this is what is often too touchy-feely to discuss overtly (so so subjective, oh my) and yet what often is not done very well
- It indeed does take quite a bit of work to build something like this and account for the variety of semantics to be compatible with. In this particular instance, not adhering to the semantics of your datastore will make your library do things you do not want it to do, and since the library here is about providing guarantees: contrary to this article here you have to be correct or your software doesn’t work.
- There are a lot of good libraries out there. Making a good library takes work. I believe idempo turned out a very, very good library. It does deserve some more spotlight, and I suck at marketing.
So, let’s look at the idempotency key decision tree:
- Receive a request. If the request contains the idempotency key header:
- Check whether this idempotency key has already been recorded, and whether there is a rendered response for it.
- If the key exists and rendered response is cached: return the cached response
- If the key exists: consider the request “in progress” and consider this request to be a concurrent request. Respond with a 409 status.
- If the key doesn’t exist: save it someplace (so that no concurrent request can begin) and enter the application code
- Once the application is done, capture the rendered response.
- If the response is idempotent (4xx error or 2xx or 3xx) cache the response
- If the response is not idempotent - release the idempotency key so that a subsequent request may succeed instead
- Return the response
This looks pretty simple, and mostly it is - this is what Ilja’s code is doing also, for the most part. Let’s imagine a hypothetical Rack middleware which does the above:
class IdempotencyKeyMiddleware < Struct.new(:app)
def call(env)
return app.call(env) unless idempo_key = env['HTTP_X_IDEMPOTENCY_KEY']
if request_in_progress?(idempo_key)
return [409, {}, ["Concurrent request in progress, try later!"]] if
elsif recorded_response_exists?(idempo_key)
return fetch_response_triplet(idempo_key)
else
record_request_started!(idempo_key)
status, headers, body = app.call(env)
if status < 500 && status >= 200
save_response(status, headers, body)
end
delete_in_progress_response(idempo_key)
[status, headers, body]
end
end
end
The implementations of request_in_progress?, recorded_response_exists? and the like are omitted here, because these are not the “tricky bits”. We will need to account for a few things: 429 is actually a code that has to be declared non-idempotent, because the client is supposed to retry that one. 409 is also not very suitable if you are already using it for something else (like validation errors) – also for us we had automatic use of the Retry-After in our JS client, so a 429 made more sense for us for a concurrent request.
We also need to add the request fingerprint (for example the URL of the request, and likely also the digest of the request body) to the idempotency key (and call it something else - like request_key).
But the bigger problem with this code though - and with most of Ilja’s examples for that matter (in the article I’ve linked above) is that they do not account well for race conditions. Specifically:
- Between
recorded_response_exists?andfetch_response_tripletthe record could disappear from the datastore 🏎. - During
fetch_response_tripletthe record could disappear from the datastore (if the read from the datastore is not atomic) 🏎. - Between
record_request_started!(just before it gets called) another request could enter and try to do the same, and get to therecord_request_started!line earlier than ours. If that happens, both our request and the other request will be allowed to doapp.call()and the idempotency guarantee is going to be violated 🏎 - Between
record_request_started!andsave_responsethe record could also disappear. Depending on the datastore semantics we might be unable to save it. 🏎. - If our
app.callcrashes we might not performdelete_in_progress_response, same if we crash before we perform our idempotent action. 🏎.
This kind of problem is fairly well known and it calls for the use of a shared lock. Given a request key of RK only one request should be able to check it out, and only one request should hold it while it is processing the request or looking for a cached response. When locks are used, we need to carefully adjust the code so that all the spots where we operate with the lock held - but also all the spots where we operate without it - can be examined and analysed for races. So, instead of using find (like Ilja is suggesting) we need to use create_or_find, but since we start on a lower level - without using ActiveRecord or Redis - we can do it in a bit more minimal fashion:
def call(env)
return app.call(env) unless env['HTTP_X_IDEMPOTENCY_KEY']
request_key = compute_request_key(env)
did_acquire_lock = acquire_lock(request_key)
return [429, {}, ['Concurrent request!']] unless did_acquire_lock
response_triplet = fetch_response_triplet(request_key)
return response_triplet if response_triplet
status, headers, body = app.call(env)
save_response(request_key, status, headers, body) if response_idempotent?(status, headers, body)
[status, headers, body]
ensure
release_lock(request_key) if did_acquire_lock
end
Note that we have collapsed the recorded_response_exists? and fetch_response_triplet into one call to avoid the race condition where our response could disappear between our check and our fetch. This implies that the fetch_response_triplet will also do something to use the most atomic datastore function we can apply.
But more importantly: we also introduced a lock, which we can either receive correctly (did_acquire_lock will be true) or get denied - in which case we know that a concurrent request is already in progress. Notice a pattern here: “tell, don’t ask” is how you can reduce race conditions fairly quickly. This is why instead of find and then create, first collapse to find_or_create - and immediately after to create_or_find which first tells the database to create the record, and then atomically finds it, although that too has a race condition – we will get there soon enough.
Let’s look at our locking in a bit more detail. If we remove other code, we see the following code paths touching it:
did_acquire_lock = acquire_lock(request_key)
release_lock(request_key) if did_acquire_lock
Doing the simplest thing first
To make these do something useful, we are going to need us a lock issuing mechanism. Since we “start small”, we will start with an in-process locking service. The simplest thing for holding a number of locks (which are just strings) would be a Set. If the string for a request key is in our set, we know a request is in progress. If the string is not in the set, we add it to our set and return true:
class IdempotencyKeyMiddleware
def initialize(app)
@app = app
@requests_in_progress = Set.new
end
def acquire_lock(request_key)
return false if @requests_in_progress.include?(request_key)
@requests_in_progress << request_key
true
end
def release_lock(request_key)
@requests_in_progress.delete(request_key)
end
...
end
Notice how we introduced yet another race condition here: our middleware is multi-threaded. Two requests can (and will!) call into acquire_lock) around the same time, and both of them may get “through” to @requests_in_progress << request_key operation. Only one of them will add the request key to the Set, but the end result will be the same - we will allow 2 concurrent requests. A Rack middleware gets instantiated once – the Rack builder creates you one copy of your application tree, and then dispatches multiple calls into it. Our locking service thus can be multithreaded.
This is why we need a Mutex here - we may only allow one thread to do things to our locks Set at the time:
class IdempotencyKeyMiddleware
def initialize(app)
@app = app
@requests_in_progress = Set.new
@requests_in_progress_mutex = Mutex.new
end
def acquire_lock(request_key)
@requests_in_progress_mutex.synchronize do
return false if @requests_in_progress.include?(request_key)
@requests_in_progress << request_key
true
end
end
def release_lock(request_key)
@requests_in_progress_mutex.synchronize do
@requests_in_progress.delete(request_key)
end
end
end
We also need to do the same when we remove our request key from the locks Set too, so that our Set#delete does not happen right between the include? and the << being called by another thread. Note that we will only lock the mutex when we are changing or reading the contents of the Set but not for the entire duration of our request - that would make our app single-threaded, and we don’t want that.
Next step: make some machinery to cache a generated response. Careful there too: Rack bodies are not rewindable and they cannot be serialized to JSON because they can be binary, and the like (but this is fairly trivial to do):
def rack_body_to_array_and_cached_version(rack_body)
[].tap do |chunks|
rack_body.each { |chunk| chunks << chunk }
end
ensure
rack_body.close if rack_body
end
Let’s recap our race condition situation now:
- Between
recorded_response_exists?andfetch_response_tripletthe record could disappear from the datastore - Fixed as we are inside the locked region there - During
fetch_response_tripletthe record could disappear from the datastore (if the read from the datastore is not atomic) Still there - Between
record_request_started!(just before it gets called) another request could enter and try to do the same, and get to therecord_request_started!line earlier than ours. If that happens, both our request and the other request will be allowed to doapp.call()and the idempotency guarantee is going to be violated - Fixed as we are inside the locked region - Between
record_request_started!andsave_responsethe record could also disappear. Depending on the datastore semantics we might be unable to save it. Fixed as we are inside the locked region - If our
app.callcrashes we might not performdelete_in_progress_response, same if we crash before we perform our idempotent action. Fixed - with in-memory locks, if our process crashes our locks table goes with it. If our app raises we will still release the lock via anensureblock.
We solved a number of the races, but we still have a couple.
- We need to coordinate the saving and deletion of the cached response with our locks somehow. Response disappearing when a lock is held violates consistency
- We need to ensure that our locks are properly released - for now this is not an issue. It will be in a second.
Now, this is all fine and well as long as we are fine running just one Puma server with a few threads. Most applications will not work like this - they will have multiple servers, all running multiple application threads. So a shared datastore of some kind is going to be needed. For us, the store of choice “by default” was the database as we have not yet introduced Redis or Memcached into the app. We found, at the time, that even though these datastores are amazing - we could get some benefits by only using one datastore if we could get by with that datastore exclusively. But at the same time - with the history of libraries like prorate - we would be getting Redis onboard, just not right now. So…
Bring us the pluggable data stores!
This, in turn, brings us to an interesting junction. When we want to work with locks, and especially distributed locks - and if we want to coordinate persistence for responses with those locks - the semantics of the datastore we pick matter. They matter a hell of a lot actually, because some of them do support “check then set”, others only support “set and recover”. Some support foreign keys which get validated, some don’t. Some are able to have native TTL support - which we needed - and some didn’t. So the difficulty turned out to be to create an API which would allow us to use different datastores for idempotency keys, but crucially with the same semantics regardless of how the implementation specific to the datastore works. So inside of our code, we would likely want to do something like this (because this is what the objects are for):
def call(env)
return @app.call(env) unless env['HTTP_X_IDEMPOTENCY_KEY']
request_key = compute_request_key(env)
did_acquire_lock = @datastore.acquire_lock(request_key)
return [429, {}, ['Concurrent request!']] unless did_acquire_lock
response_triplet = @datastore.fetch_response_triplet(request_key)
return response_triplet if response_triplet
status, headers, body = @app.call(env)
@datastore.save_response(request_key, status, headers, body) if response_idempotent?(status, headers, body)
[status, headers, body]
ensure
@datastore.release_lock(request_key) if did_acquire_lock
end
Now, instead of calling our own methods for locks, we would be calling into this arbitrary @datastore implementation, which would then use either MySQL, or Redis, or the in-memory Set setup, whichever would be more applicable. Now, how would it look like? For our in-memory setup it would be pretty straightforward:
class LocalIdempotencyStore
def initialize
@requests_in_progress = Set.new
@requests_in_progress_mutex = Mutex.new
@saved_requests = {}
end
def fetch_response_triplet(request_key)
return unless @saved_requests[request_key]
Marshal.load(@saved_requests[request_key])
end
def save_response(request_key, *triplet)
@saved_requests[request_key] = Marshal.dump(triplet)
end
def acquire_lock(request_key)
@requests_in_progress_mutex.synchronize do
return false if @requests_in_progress.include?(request_key)
@requests_in_progress << request_key
true
end
end
def release_lock(request_key)
@requests_in_progress_mutex.synchronize do
@requests_in_progress.delete(request_key)
end
end
end
Bring us the database!
We know that save_response and fetch_response_triplet are not going to be called without the lock being held, because our lock is indefinite (and stored in memory). Now let’s up this a notch and implement the same based on ActiveRecord - so that our requests go into the database.
class ARIdempotencyStore
def acquire_lock(request_key)
# We presume there is a `requests_in_progress` table with a `request_key` column which has a uniqueness constraint,
# that is crucial!
RequestInProgress.create!(request_key) && true
rescue ActiveRecord::RecordNotUnique
false
end
def release_lock(request_key)
RequestInProgress.where(request_key: request_key).delete_all
end
...
end
but here already be dragons. Unlike our LocalIdempotencyStore our implementation here is not immune to sudden process death or termination. If we can ensure then yes - our held lock will be released. But if our process crashes outright (the server loses the network connection, or shuts down, or the application gets killed abruptly) our locking record will stay in the database indefinitely! And no client will be able to call this endpoint again with this idempotency key, as every request would be considered concurrent. Congratulations: we introduced a race condition due to different datastore semantics. We can circumvent that by using advisory locks instead of rows. If our process crashes, it releases the database connection (which is holding the lock) and that, in turn, will make MySQL release the lock itself:
class ARIdempotencyStore
def acquire_lock(request_key)
safe_key = Digest::SHA256.hexdigest(request_key)
result = ActiveRecord::Base.connection.select_value("SELECT GET_LOCK('%s', 0)" % safe_key)
result == 1 # 1 means we did acquire the lock
end
def release_lock(request_key)
safe_key = Digest::SHA256.hexdigest(request_key)
ActiveRecord::Base.connection.select_value("SELECT RELEASE_LOCK('%s')" % safe_key)
end
...
end
You want to do the same with PostgreSQL? Different locking functions, slightly different semantics again, more implementation changes.
Bring us the Redis! (and more divergent semantics)
Then we bring Redis into the mix. With Redis, we have some prior art with locking in the form of the Redlock algorithm, of which we won’t be needing as much. Even in our fairly high-volume use case there is no use of Redis clusters, AWS ElastiCache only provides primary and failover replica. So, let’s port our lock implementation to a single-node Redlock. Since we already are using ConnectionPool for Redis connections (and you should too) we will incorporate it directly:
class RedisIdempotencyStore
def initialize(redis_connection_pool)
@pool = redis_connection_pool
end
def acquire_lock(request_key)
@token = SecureRandom.bytes(16)
@pool.with do |redis|
return redis.set(lock_key, @token, nx: true, ex: LOCK_TTL_SECONDS)
end
end
def release_lock(request_key)
raise "No acquired lock" unless @token
lua_script = <<~EOS
redis.replicate_commands()
if redis.call("get",KEYS[1]) == ARGV[1] then
-- we are still holding the lock, release it
redis.call("del",KEYS[1])
return "ok"
else
-- someone else holds the lock or it has expired
return "stale"
end
EOS
@pool.with do |redis|
result = redis.eval(lua_script, keys: [lock_key], argv: [@token])
raise "Lock was lost while we held it" unless result == "ok"
end
@token = nil
end
Note that here we have to contend with another bit of Redis semantics: since we do not have the luxury of automatic lock release if our process dies, and we do not have the luxury of automatic lock refresh - we need to set a TTL for our lock. If our process dies (and we do not manage to get to the ensure) our lock will still be automatically released after some time. The locking mechanism is roughly this:
- Generate a random payload (the token)
- Set that token to the lock key in Redis, but conditionally (using SETNX). If it could be set - we acquired the lock. If it could not - someone else holds the lock.
- Once we are done - run a Lua script to delete the lock key. If the value of the lock key is a different token - we have lost our lock during execution (for example our execution took too long)
Note that we also now have a bit of data per request, which is specific not only to the value of the request_key but also to our executing request - the @token. This token must also be protected from thread races – remember our in-memory implementation? So to facilitate that, let’s change our API from using a single datastore instance for our middleware to using a single datastore instance per request, instantiated at call:
def initialize(app, datastore_factory:)
@app = app
@datastore_factory = datastore_factory
end
def call(env)
return @app.call(env) unless env['HTTP_X_IDEMPOTENCY_KEY']
request_key = compute_request_key(env)
store = @datastore_factory.new
did_acquire_lock = store.acquire_lock(request_key)
return [429, {}, ['Concurrent request!']] unless did_acquire_lock
response_triplet = store.fetch_response_triplet(request_key)
return response_triplet if response_triplet
status, headers, body = @app.call(env)
store.save_response(request_key, status, headers, body) if response_idempotent?(status, headers, body)
[status, headers, body]
ensure
store.release_lock(request_key) if did_acquire_lock
end
Once we do this, we can see that every single method of our datastore object wants this request_key and we also instantiate our datastore for that specific request key. If I remember right, this is what instance variables are very good for:
class RedisIdempotencyStore
def initialize(request_key)
@request_key = request_key
@token = SecureRandom.bytes(16)
end
def redis_lock_key
"idempotency_key_lock:#{@request_key}"
end
def acquire_lock
@pool.with do |redis|
return redis.set(redis_lock_key, @token, nx: true, ex: LOCK_TTL_SECONDS)
end
end
def release_lock
lua_script = <<~EOS
redis.replicate_commands()
if redis.call("get",KEYS[1]) == ARGV[1] then
-- we are still holding the lock, release it
redis.call("del",KEYS[1])
return "ok"
else
-- someone else holds the lock or it has expired
return "stale"
end
EOS
@pool.with do |redis|
result = redis.eval(lua_script, keys: [redis_lock_key], argv: [@token])
raise "Lock was lost while we held it" unless result == "ok"
end
end
and our middleware code evolves like this:
def initialize(app, datastore_factory:)
@app = app
@datastore_factory = datastore_factory
end
def call(env)
return @app.call(env) unless env['HTTP_X_IDEMPOTENCY_KEY']
request_key = compute_request_key(env)
store_for_request = @datastore_factory.new(request_key)
did_acquire_lock = store_for_request.acquire_lock
return [429, {}, ['Concurrent request!']] unless did_acquire_lock
response_triplet = store_for_request.fetch_response_triplet
return response_triplet if response_triplet
status, headers, body = @app.call(env)
store_for_request.save_response(status, headers, body) if response_idempotent?(status, headers, body)
[status, headers, body]
ensure
store_for_request.release_lock if did_acquire_lock
end
We solve a few inconveniences, all in one go:
@tokenwill always be set now, we do not have to account forrelease_lockgetting called without one- There will be no thread-races, as every
storewill be thread-local - We do not have to pass the
request_keyaround all the time
but you will see that we have lost our @redis_pool instance variable. Since the call method of the middleware is going to instantiate us a datastore on every invocation, we must find a different way to shuttle the Redis connection pool into our datastore object. This requires yet another change: instead of instantiating the middleware like this:
use IdempotencyKeyMiddleware, datastore_factory: RedisIdempotencyStore
we are going to change the setup and allow the datastore to be configured during initialization:
use IdempotencyKeyMiddleware, datastore: RedisIdempotencyStore.new(Redis.new)
This is a pattern I tend to use quite often - think about how you want your API to be consumed, and let that inform the implementation. To make this work, we are going to relocate our request key related activities into another object which our datastore can create. So, yet another change:
def initialize(app, datastore:)
@app = app
@datastore = datastore
end
def call(env)
return @app.call(env) unless env['HTTP_X_IDEMPOTENCY_KEY']
request_key = compute_request_key(env)
store_for_request = @datastore.for_request(request_key)
did_acquire_lock = store_for_request.acquire_lock
return [429, {}, ['Concurrent request!']] unless did_acquire_lock
response_triplet = store_for_request.fetch_response_triplet
return response_triplet if response_triplet
status, headers, body = @app.call(env)
store_for_request.save_response(status, headers, body) if response_idempotent?(status, headers, body)
[status, headers, body]
ensure
store.release_lock(request_key) if did_acquire_lock
end
and our Redis class implementation will then change again (and will actually become two classes, but the caller doesn’t care):
class RedisIdempotencyStore
def initialize(redis_connection_pool)
@pool = redis_connection_pool
end
def for_request(request_key)
RequestContext.new(@pool, request_key)
end
class RequestContext
def initialize(redis_pool, request_key)
@request_key = request_key
@token = SecureRandom.bytes(16)
@redis_pool = redis_pool
end
def redis_lock_key
"idempotency_key_lock:#{@request_key}"
end
def acquire_lock
@pool.with do |redis|
return redis.set(redis_lock_key, @token, nx: true, ex: LOCK_TTL_SECONDS)
end
end
def release_lock
lua_script = <<~EOS
redis.replicate_commands()
if redis.call("get",KEYS[1]) == ARGV[1] then
-- we are still holding the lock, release it
redis.call("del",KEYS[1])
return "ok"
else
-- someone else holds the lock or it has expired
return "stale"
end
EOS
@pool.with do |redis|
result = redis.eval(lua_script, keys: [redis_lock_key], argv: [@token])
raise "Lock was lost while we held it" unless result == "ok"
end
end
end
and similar for other store implementations. Once that is tackled, we end up with another peculiar race condition, which has been well described by Martin Kleppmann in his rebuttal of the Redlock algorithm: namely, the lock TTL can expire while the concurrent request is still in progress. This is why we raise an exception in our release_lock method - if we do not hold the lock we should signal it somehow. The timeline for the lock getting lost looks like this:
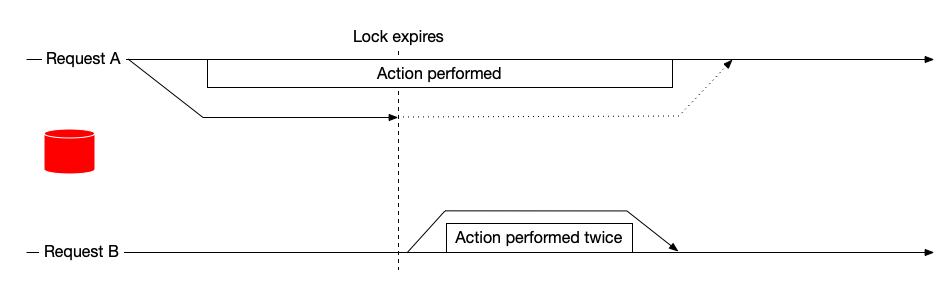
We have two “bad things” which can happen:
- A concurrent request is going to be allowed through (see the figure above)
- Cached response is going to be overwritten, with an unspecified request winning the write. A “stolen write” will look like this:
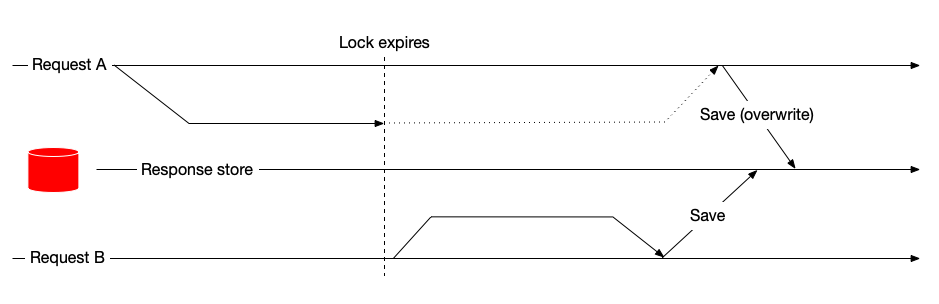
One of those we can only prevent by using a more robust locking service. If you have a database with advisory locks - great! you can use it, but you will need to contend with expiring stored responses manually. But if you want to truck along with Redis - and Redis is a very, very juicy tool for this kind of usage - we will need to do some more work, all to satisfy the semantics. What we are going to do is add a pre-condition, which we are going to define as follows:
The cached response may only be written to the datastore as long as the lock is still held by this particular request. Thus…
Bring us the lock and response persistense synchronization!
Instead of doing just this:
def save_response(response_triplet)
marshaled_response = serialize_response(response_triplet)
@pool.with do |redis|
redis.set(redis_stored_response_key, marshaled_response, ex: ttl_for_stored_responses)
end
end
we will have to do this:
def save_response(response_triplet)
marshaled_response = serialize_response(response_triplet)
@pool.with do |redis|
held_lock = redis.get(redis_lock_key)
if held_lock == @token
redis.set(redis_stored_response_key, marshaled_response, ex: ttl_for_stored_responses)
end
end
end
We check whether the token stored in the lock key still is the one that belongs to us, and if it is - we allow the save. But here be dragons again - we just introduced another race condition. If the lock key gets expired (or deleted) between our call to redis.get and redis.set we will potentially overwrite someone else’s response. So yet again we need to revert to using Redis scripts to guarantee atomicity. Enter more Lua:
def save_response(response_triplet)
set_with_ttl_if_lock_held_lua_script = <<~EOS
redis.replicate_commands()
if redis.call("get", KEYS[1]) == ARGV[1] then
-- we are still holding the lock, we can go ahead and set it
redis.call("set", KEYS[2], ARGV[2], "px", ARGV[3])
return "ok"
else
return "stale"
end
EOS
@pool.with do |redis|
redis.eval(set_with_ttl_if_lock_held_lua_script, keys: [redis_lock_key, redis_stored_response_key], argv: [@token, marshaled_response])
end
end
Remember how I said that coordinating the lock and the saving/loading of the cached response will be necessary earlier in the article? Here it is then: the two actually have to be managed together, because the persistence of the response body must be coherent with the locks, otherwise data corruption can occur.
So, from our former list, we have fixed 2 races out of 3:
- Our request loses the lock, another concurrent request starts, and we write out our cached response before the other request does - Fixed
- Our request loses the lock, another concurrent request starts, and it writes its cached response out which we then overwrite - Fixed
- Our request loses the lock, another concurrent request starts, and neither write out the cached response because the race condition gets detected Undefined
We are not able to prevent the concurrent request from starting, but we are able to prevent its side effect from being persisted - which is already a win. For the concurrent request the only sensible thing to do is to document that in case of a lost lock a concurrent request may be started and move on. Really: we can bikeshed about this for a while, but like I mentioned previously – here we are either correct or not correct and for the latter, it is a much better choice to warn the user of the software upfront.
The final API
After all of the above, we end up with something like this:
def call(env)
@app.call(env) unless idempotent_request_and_idempotency_key?(env)
request_key = extract_request_key(env)
@datastore.with_lock(request_key) do |store|
return stored if stored = store.lookup
response = @app.call(env)
store.save(response)
end
rescue ConcurrentRequest
[409, {}, []]
end
and the key module which we need to implement it would look approximately like this:
class DataStore
def with_lock(request_key)
did_acquire = acquire_lock(request_key)
raise ConcurrentRequest unless did_acquire
store_for_this_request = Store.new(request_key)
yield(store_for_this_request)
end
class Store < Struct.new(:request_key)
def lookup
# ...some code to retrieve the triplet for the request
end
def save(status_headers_and_body)
# ...some code to save the triplet for the request
end
end
end
The DataStore implementation can then be swapped to use different persistence mechanisms / systems. We hold by the following desirable properties:
- There is only one place where we have to pass our
request_keyto the data store (good) - Everything that is supposed to happen while the lock is held goes into the block (good)
- We use exceptions to signal a concurrent request, so we can implement one “divergent path” for the entire flow (good)
- We did set up an API which is not obvious (bad). But hopefully this article explains the choices made.
- Serializing and unserializing the response is somehow the responsibility of the datastore (bad), let’s fix that:
class Store < Struct.new(:request_key)
def lookup
# ...some code to retrieve the marshaled binary string with response
end
def save(marshaled_binary_string_with_response)
# ...some code to save the marshaled response
end
end
- We also need to be able to set the TTL for our saved response and it is not available yet. Let’s fix that:
class Store < Struct.new(:request_key)
def lookup
# ...some code to retrieve the marshaled binary string with response
end
def save(marshaled_binary_string_with_response:, ttl_seconds:)
# ...some code to save the marshaled response with expiry
end
end
How problematic are the stale locks?
Needless to say, we did get some of those stale locks in production too! At WeTransfer scale, anything that may happen undoubtedly will happen. These cases were few and far between (maybe one in a million requests). Were they critical for us? No, not really. Would they have been critical for us if our requests were doing this?
def call(env)
params = parse_params(env)
account = Account.find(params[:id])
account.debit(params[:amount])
end
Of course it would, at which point…
You still have to pick your poison
If we rely on the idempotency keys to prevent a double debit we would then have a choice between using the database store and lock (for more guarantees, and less performance) or using the Redis store and lock, and then add, say, database locks just for this case. If we haven’t had the code for using advisory locks already in the application (which we did) we could have used with_advisory_lock as a supplement for our idempotency key just in this case:
def call(env)
params = parse_params(env)
account = Account.find(params[:id])
ik = env.fetch('HTTP_IDEMPOTENCY_KEY')
Account.with_advisory_lock(ik) do
account.debit(params[:amount])
end
end
Or we could make our own store implementation, and use the database for locks and Redis for storing responses.
It ain’t easy
No, really - there are quite a few other things in idempo where even more work was required. I just outlined the locks as the most critical part of it all, and how the design evolved to satisfy the locking paradigms of various datastores. Just to name a few other items:
- Saved responses have to expire after some time. At the minimum, with DB-drive persistence we have to have an index on
created_atto do bulk expiries. - The called app should be able to control how long the cached response gets persisted for (we added a header for that)
- Saving responses only makes sense when the response size is not too big for the datastore. Do you want to save a 1GB ZIP file response?
- Serializing responses should use something that does not break when Ruby versions change (so no
Marshal) yet it must support binary data (so no JSON and no YAML either). We had to settle on Messagepack in the end - Stored responses do not have to be aggregated, and APIs produce responses that compress very well. Responses are thus deflated on save
- Saving a Rack response needs reading the Rack response body. And a Rack response body might be non-rewindable, so when we do cache we have to replace the response body we return with an Array of cached strings. This is also done only if the response can be sized ahead of time and small enough.
- Since idempotency keys are actually a “poor man’s version” of
ETag-based caching, some extra headers of the request need to be mixed into therequest_key- for example theAuthorizationheader, otherwise you can expose yourself to some pretty serious exploits. - Some datastores take TTLs in seconds, some take them in milliseconds. What is the lowest common denominator?.. etc.
- An app must be permitted to opt out of response caching entirely (some of our responses have signed URLs, those have limited TTL themselves and we want them to be fresh)
- We need to implement advisory locks for PostgreSQL too - and the lock key there is a signed bigint, not a string.
For example, here is the main call from idempo in its entirety (compare to the chunks above):
return @app.call(env) if request_verb_idempotent?(req)
return @app.call(env) unless idempotency_key_header = extract_idempotency_key_from(env)
# The RFC requires that the Idempotency-Key header value is enclosed in quotes
idempotency_key_header = unquote(idempotency_key_header)
raise MalformedIdempotencyKey if idempotency_key_header == ''
fingerprint = compute_request_fingerprint(req)
request_key = "#{idempotency_key_header}_#{fingerprint}"
@backend.with_idempotency_key(request_key) do |store|
if stored_response = store.lookup
Measurometer.increment_counter('idempo.responses_served_from', 1, from: 'store')
return from_persisted_response(stored_response)
end
status, headers, body = @app.call(env)
if response_may_be_persisted?(status, headers, body)
expires_in_seconds = (headers.delete('X-Idempo-Persist-For-Seconds') || DEFAULT_TTL).to_i
# Body is replaced with a cached version since a Rack response body is not rewindable
marshaled_response, body = serialize_response(status, headers, body)
store.store(data: marshaled_response, ttl: expires_in_seconds)
end
Measurometer.increment_counter('idempo.responses_served_from', 1, from: 'freshly-generated')
[status, headers, body]
end
In conclusion
We did finish and deploy it, and it works really, really well. It took us 2 throwaway implementations before we arrived at this one, and a few more trials to pick the best datastore. Maybe with a story like this it can be more insightful to see what it really takes to build a good library, and how an API comes to be designed. We do not publish enough details about how software gets designed, which makes it less likely that our software will be found and used. I don’t want this to happen to idempo. Making a gem which does a seemingly tiny thing can be devilishly complex, and switchable implementations for things are actually useful. So: hope you enjoyed the ride, go forth and use idempo 🤗
And when you come to design a gem, write down some traveler’s diaries for us all to enjoy too. We in general do not give enough attention to how software gets designed, and that’s a shame.