
Exploring batch caching of trees
From my other posts it might seem that I am a bit of a React hater - not at all. React and related frameworks have introduced a very powerful concept into the web development field - the concept of materialised trees. In fact, we have been dealing with those in Rails for years now as well. Standard Rails rendering has been a cornerstone of dozens of applications to date, and continues to be so. But once you see “trees everywhere” it is hard not to think about optimising using trees. So let me share an idea I’ve had recently which might as well be very neat.
🧭 I am currently available for contract work. Hire me to help make your Rails app better!
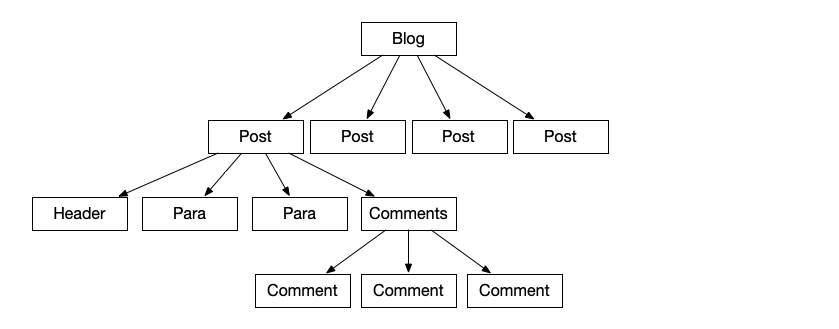
When we look at our React components, we will see it output a tree of rendered components (how exactly it “outputs” is not relevant for the conversation). Let’s look at a small tree for a hypothetical blog, just like the one you are reading now. We have a number of posts, and every post has a header and a few paragraphs of copy. A post also has a collection of Comments attached:
The same can be said of Rails templates, really:
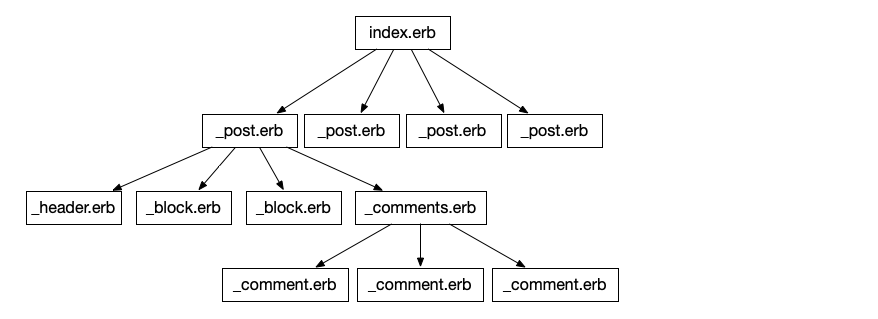
Granted, some of these can be actual chunks of HTML that get output - for example, a _header.erb could be just a chunk of bytes with <h2>My amazing post</h2> inside. But the important point which we are going to explore is that it is still a tree of some description.
The tree need not be static. Both with React and with Rails templates the output of the tree may change depending on the logic inside the tree nodes themselves. For example:
<%= render partial: "admin_actions" if current_user.admin? %>
is a very basic piece of conditional logic embedded into the template itself. If our current_user is admin? there is an extra node added to the tree for their admin actions. Conditional rendering of React components would be doing approximately the same thing.
A tree by the waterfall
What becomes important - and is a focus of a lot of attention in the JS community now - is data loading. Same applies to us in Rails-land. Here is some data we need for displaying our blog:
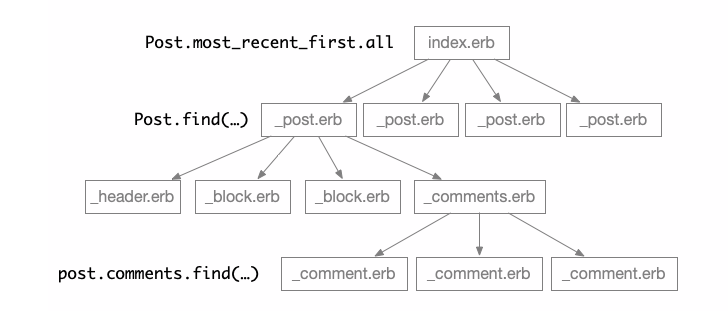
And any app I’ve seen of any measurable size would do these nested views, and would come to the problem of “N+1 queries”. Combating those is a viable - and necessary - thing to do, but another approach has been very popular with Rails for a decade now, and it is called “Russian doll caching”. It relies on “things” in the application having a #cache_key they can be reliably identified with, and those cache keys can be used to cache nested pieces of output. Branches, really:
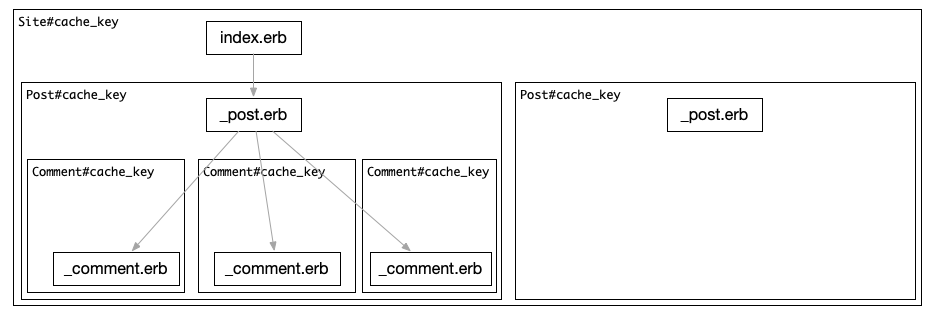
When we render a view, we follow the following logic for this tree:
if output = cache.get(site.cache_key)
return output
else
render(partial: "site", locals: {site:})
end
and inside of the _site.erb partial, we will do:
site.posts.published.most_recent_first.each do |post|
if output = cache.get(post.cache_key)
buffer << output
else
buffer << render(partial: "site", locals: {site:})
end
end
and the same for _comment.erb
post.comments.each do |comment|
if output = cache.get(comment.cache_key)
buffer << output
else
buffer << render(partial: "comment", locals: {comment:})
end
end
Imagine all of our interacting partials (_site.erb, _post.erb and _comment.erb) can be cached using a cache key of their respective model. If we do caching for every one of them, rendering our blog with all cache misses is going to be 1 + 1 + 3 = 5. Every cache miss is going to be a roundtrip to a cache store. Let’s imagine it costs us 5 milliseconds, and we have a Site with 20 posts, and every post has at least 9 comments 1 + (20 * 9) = 181 This is already somewhat sizeable, and gives us the following prediction for end-user latency (just for our server rendering part - the client hasn’t even started receiving data at this stage) - (1 + (20 * 9)) * 5 = 905, close to a whole second just to get the cache misses. This problem is also known as waterfalling in the JS circles - remember how miserable it makes you when your JIRA screen painstakingly pops up pane after pane? This is the same, but worse - while the server is busy doing this work, the client will hardly see any progress. Loaded data begets more loaded data, until the entire tree has been resolved.
What this actually does in terms of tree traversal is called depth first traversal - it goes to a node which hasn’t been rendered yet, and tries an immediate cache get for that particular node. If there is a cache hit - it takes the cached data and substitutes it into the output. If there isn’t - the node gets rendered by running its template. During rendering, the node in turn traverses “into” itself, and tries to retrieve its children from the cache, one by one.
Cheaper in bulk
For this, we can do some optimisations. Imagine our comment rendering does look like this instead:
render(collection: post.comments, partial: "comment", cached: true)
This enables an optimisation which is built in into recent Rails, where a CollectionRenderer, where the renderer will first do a Rails.cache.read_multi(...) on all of the cache_key values for your Comment models. It will then only run the rendering via the _comment.erb partial for the Comment models for which no cache has been found.
The number of cache roundtrips with all misses is going to be 1 + (20 * 2) = 41, way less than our previous approach where we had 1 + (20 * 9) = 181. In addition, CollectionRenderer is going to write_multi to fold the saving of the cached data into one roundtrip per collection rendered.
In terms of tree traversal, this is a combination of depth-first traversal (traversing each post partial of the blog template) and breadth-first traversal (rendering a collection of Comments).
But what if we could do better?
The broader picture
The CollectionRenderer makes use of a great property of collections - it is known which template (partial) has to be executed for every collection member, and the collection members are known ahead of time. Stack those collection renderers, and you could get some good performance increases. Walking a tree would look like this then:
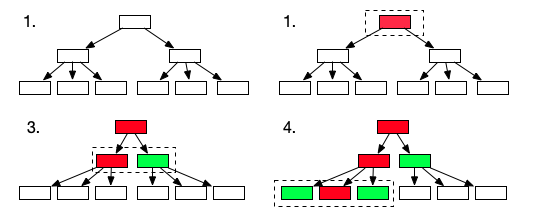
Green nodes are what we managed to retrieve from the cache, red ones are cache misses. Every dashed rectangle is a cache fetch. It all seems fine, but there is a catch. Imagine we have a tree like this:
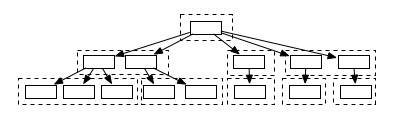
Here, the number of roundtrips is going to grow quickly, because even though we are doing a breadth-first traversal of a particular collection, we still can have multiple collections at the same level - and therefore, multiple cache roundtrips. For example, if we have 3 _post.erb partials, even with a collection renderer first there will be a read_multi for the comments of the first Post, then another for the comments of the second - and so forth.
In this example, every dashed box is a cache fetch (and a potential cache miss). We have 1 roundtrip at the root of the tree, then 3 roundtrips ad the second level, and 4 roundtrips one level further down. This can quickly escalate into a waterfall of cache misses. Imagine one such miss taking 5ms, and with a tree with an “unlucky” configuration you will quickly waterfall into seconds of render time.
There is an approach to this which React Suspense is using, and I wanted to try this approach for some time though - albeit as a proof-of-concept. What if we were to turn our rendering into a three-phase process? Instead of having three states (“white” for “untraversed”, “green” for “from cache” and “red” for “rendered fresh”) we would have four? The extra state (let’s call it “orange”) would mean that we could not retrieve the node from the cache, but we haven’t started rendering it either - we want to examine whether its children can be retrieved from cache first.
Then our traversal could work like this:
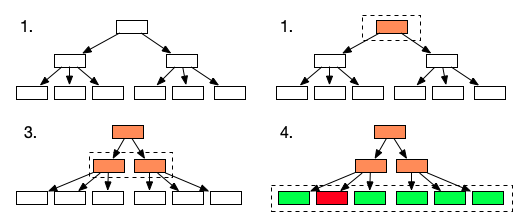
We would go to the root node first. We would try to retrieve it from the cache, and have a miss - which would then move the node into an “unfolding” state. “Unfolding” means that we want to examine the node’s children before we try to produce a rendered result. The root node has two child nodes, which we both “unfold” as well - we thus do a second cache fetch, but we do it in a batch. These two nodes become unfolded, and they, too, are not cached. We discover that these nodes have children too, and attempt a retrieval for them. The beauty of this approach is that the number of cache fetches will be at most D where D is the depth of our render tree.
In our “wider tree” example, we would do just 3 cache fetches - and if all nodes at a certain level of the tree get cache hits, even less:
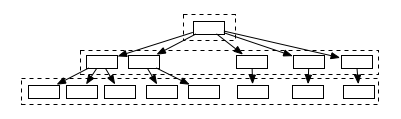
This allows for substantial speedups. If we go back to our previous example of Site -> Post -> Comment the number of cache roundtrips would be 3, always.
Moreover, we can defer the writeout of everything that has been rendered into the “pass” as well - once a level of the tree gets resolved (all nodes turn from “orange” to either “green” or “red”) that level can be written into the cache with one roundtrip as well - using write_multi.
This works using an algorithm like this:
def node_to_fragments(node, cache_store)
root_node = RenderNode.new(node)
loop do |n|
tree_of_keys = root_node.collect_dependent_cache_keys
tree_of_values = hydrate(tree_of_keys, cache_store)
root_node.pushdown_values_from_cache(tree_of_values)
keys_to_values_for_cache = {}
root_node.collect_rendered_caches(keys_to_values_for_cache)
cache_store.write_multi(keys_to_values_for_cache) if keys_to_values_for_cache.any?
return root_node.fragments if root_node.done?
end
end
which iteratively attempts to resolve the given node until it goes from “white” to “green”, with one pass per level. This algorithm can be used, for instance, for GraphQL cache retrieval - as most objects will be cacheable by a combination of their GraphQL fields and their cache_key value. Same for DOM trees, same for any other tree structure with “unconditional” output.
Dealing with the imperative
Let’s loop back to the beginning. Collections with “unconditional rendering” are great and very well-suited all amazing, of course, but most Rails templates are imperative, not “containerized”. In fact, the same problem plagues the React rendering layer and Nikita recently wrote a great article on a related topic, where the identity of UI components comes up as a key property for these tree-like renders.
But templates are not like that. They are more like that:
<h1>Hello, <%= current_user.display_name %></h1>
<% if current_user.admin? %>
<button>Moderation tools</button>
<button>Scoring</button>
<% end %>
and the like. So the template is not a “flat collection” of some kind, where the content can be recalled just by looking at the identities of the members - it is linear, executable code. Could we apply a similar optimisation to a template like this, while preserving our sanity? We could, it turns out - but that requires us to put things on their head a bit, and render asynchronously. Stay tuned for Part 2, where we are going to explore exactly that.
All of these concepts are applicable anywhere - I suspect they would be the most useful in the new brave world of JS frameworks, but by the same token - likely the ones that need it already are using it.
Some code, perhaps?
Sure! You will find a proof-of-concept on Github under julik/unfolding If you would like to explore this topic further, please do get in touch over email, or find me on Mastodon!
See you next time!