
On the way to step functions: geneva_drive
This is the concluding article in the series On the Way to Step Functions - you will find the other articles linked below:
- On the way to step functions: Part 1
- On the way to step functions: Part 2
- On the way to step functions: Part 3
We have established a few important points so far.
- The spirit, the desiderata of durable execution comes from the desire to have marshalable stacks - which are unachievable.
- Second-best option are workflows, which are actually DAGs under the hood.
- The DAG definition and the code inside the nodes are two separate worlds with different semantics.
- Systems that pretend they are one body of execution will make you hurt.
So: how do we apply these insights to Rails? Enter geneva_drive.
We have to re-learn to walk alone
Reading the article about Nexus that Obie has posted I got absolutely struck. Yes, it can be said without a shade of doubt that the modern way of building software, the late-2025-way with Opus 4.5 in the picture, is markedly different from the one we operated in for the last decade (or more).
I haven’t been sitting on my hands either. One of my smaller pursuits, now that I am a proud self-employed raconteur, has been moneymaker - a piece of kit I wanted for all the business aspects of the said raconteurship. Think:
- basic accounting
- bank statements and balances
- invoicing
- time tracking
- …all of that - across several projects, clients and managing entities
And, out of principle, I’ve decided to take my chances and release the reins - let the models “drive” the application much more than I did in the past 6 months or so. Because it is important to learn, first and foremost - how to care less about code.
And my experience has not been dissimilar from what Obie describes, with a few important differences. But what struck me much stronger is how other humans fit into this.
Let me explain. If you squint, you will notice one element missing from Obie’s story: other team members.
On the way to step functions: the two worlds
This is the next article in the series On the Way to Step Functions - you will find the other articles linked below:
- On the way to step functions: Part 1
- On the way to step functions: Part 2
- On the way to step functions: Part 3
- On the way to step functions: Part 4
We have highlighted that DAGs are actually the underpinning of any workflow/durable computation engine (barring serializable continuations). I would like to highlight another aspect of that reality: that there are two worlds.
TL;DR - if you are a Rails user and that topic interests you, skip away to geneva_drive which is pretty much how I feel we “should do it” in Rails-land.
On the way to step functions: it is actually a DAG
This is the next article in the series On the Way to Step Functions — you can find the first article in the series here. Previously, I have outlined the ambient desire in the field (marshalable stacks) and described why that is largely unachievable. But if imperative invocations can’t bid us consolation, what could?
DAGs, in fact.
If you are impatient (and a Rails user) - just head to the geneva_drive repo for the grand reveal.
This post is part of a series:
On the way to step functions: dreams of marshalable stacks
Lately, it has been a great challenge to get into the world of durable execution. Granted, in the world of web applications we often do not need it. However, anyone who has come in contact with electronic payments, money orders, verifications - will likely encounter a need for durable execution.
The juggernauts in the space are, of course, Temporal.io - with the recently emerging contender restate following in its footsteps. Both are based on the premise of sagas, controlled by a separate service.
There is also DBOS and now there is also absurd and the Vercel Workflow.
As it happens, meeting Bouke when I joined Cheddar has spurred my interest in Temporal. I knew someone who did work on the payments infrastructure at Uber (where Temporal came from), and intellectually the problems in the space are just very stimulating. However, as luck would have it, it would take another 2 years at Cheddar before a need would arise for actually using durable execution, in actual features. And in the course of implementing it, a few things turned out to be very invigorating indeed. So, before we go into any libraries or solutions: let’s just contemplate.
However, if you are impatient (and a Rails user) - just head to the geneva_drive repo for the grand reveal.
This post is part of a series:
Making Rails Global IDs safer
The new LLM world is very exciting, and I try to experiment with the new tools when I can. This includes building agentic applications, one of which is my personal accounting and invoicing tool - that I wrote about previously
As part of that effort I started experimenting with RubyLLM to have some view into items in my system. And while I have used a neat pattern for referencing objects in the application from the tool calls - the Rails Global ID system - it turned out to be quite treacherous. So, let’s have a look at where GlobalID may bite you, and examine alternatives and tweaks we can do.
What are Rails GIDs?
The Rails global IDs (“GIDs”) are string handles to a particular model in a Rails application. Think of it like a model URL. They usually have the form of gid://awesome-app/Post/32. That comprises:
- The name of your app (roughly what you passed in when doing
rails new) - The class name of the model
- The primary key of the model
You can grab a model in your application and get a global ID for it:
moneymaker(dev):001> Invoice.last.to_global_id
Invoice Load (0.3ms) SELECT "invoices".* FROM "invoices" ORDER BY "invoices"."id" DESC LIMIT 1 /*application='Moneymaker'*/
=> #<GlobalID:0x00000001415978a0 @uri=#<URI::GID gid://moneymaker/Invoice/161>>
Rails uses those GIDs primarily in ActiveJob serialization. When you do
DebitFundsJob.perform_later(customer)
where the customer is your Customer model object which is stored in the DB, ActiveJob won’t serialize its attributes but instead serialize it as a “handle” - the global ID. When your job gets deserialized from the queue, the global ID is going to get resolved into a SELECT and your perform method will get the resulting Customer model as argument.
All very neat. And dangerous, sometimes - once LLMs become involved.
What does "intuitive" even mean?
Two remarkable posts on HN today: the new release of Affinity is now free and Canva-subsidized and Free software scares normal people
There is a bit to unpack as to why these two are related: the first is about Affinity, which is a remarkable and very feature-complete suite of applications for graphics, and the other is about Handbrake having an “intimidating” UI. The two are in perfect connection, for an important reason: we often parade “intuitiveness” as a virtue, but with applications that are tools very few people take the effort to unpack what that coveted intuitiveness is. Or should be.
Delete your old migrations, today
We get attached to code - sometimes to a fault. Old migrations are exactly that. They’re digital hoarding at its finest, cluttering up your codebase with files that serve absolutely no purpose other than to make you feel like you’re preserving some kind of historical record.
But here’s the brutal truth: your old migrations are utterly useless. They’re worse than useless - they’re actively harmful. They’re taking up space, they are confusing (both for you and new developers on the project), and they give you a false sense of security about your database’s evolution.
If your database is out-of-sync with schema.rb you need to solve that problem anyway, and - if anything - the migrations make that problem worse.
The little Random that could
Sometimes, after a few pints in a respectable gathering of Rubyists, someone will ask me “what is the most undervalued module in the Ruby standard library?”
There are many possible answers, of course, and some favoritism is to be expected. Piotr Szotkowski, who untimely passed away this summer, did a wonderful talk on the topic a wee while back.
My personal answer to that question, however, would be Random. To me, Random is a unsung hero of a very large slice of the work we need to do in web applications, especially so when we need things to be deterministic and testable. So, let’s examine this little jewel a bit closer.
Actually doing things in user's time zone
My previous article about timezones turned out to be useful for quite a few folks, which makes me happy. One candle lights another.
Ben Sheldon asked about then actually doing something with those converted times. How do you actually send a newsletter every morning on every working day, regardless of what the user’s time zone is?
There are a number of approaches to this - once you know the UTC time of the delivery. I will cover a few of them, including the one I prefer. Let’s wind the clocks!
The boss of it all
The recent Ruby Central tragedy has me in shambles, honestly. It cuts deep at the very spot where I am feeling the most insecurity and the most disenfranchisement.
The crux of the issue is creative control. Writing software is a creative endeavor, and we are just now barely getting to the understanding that even though free software promises open source, it does not promise open governance or shared ownership. Something made by a person is their creation, and in the world of pervasive corporate grift and endless growth-at-any-cost it remains one of the few, and - to my view - purest - forms of being attached to what you produce. Having creative control and exercising it is the ultimate form of caring - something that has become a dangerous trait in today’s software organizations.
I’ve bumped into Abdelkader Boudih a couple of times online, and - frankly - was somewhat put off because I don’t like it when people become rude towards me - personally - too soon. You may have a heated debate with me and we can call each other names, but we have to share a dram of liquor first. But also - because I am biased against “rude by default” as it is something I grew up in.
Man, all I can say - I owe you an apology.
Scheduling things in user's time zone
Doing something at a time convenient for the user is a recurring (sic!) challenge with web applications. And the more users you have across a multitude of time zones, the more pressing it becomes to do it well.
It is actually not that hard, but it does have a few fiddly bits which can be challenging to put together. So, let’s do some time traveling.
Illegible perception
Good ideas are worth disagreeing with. Sean Goedecke posits that organizations implement process to have legibility – a very interesting idea. However, I see it differently.
It is not about legibility but it is about perception of legibility. Does the CEO look at burndown charts in your project management tool? Maybe, but highly unlikely. Does the head of product look at the key user flows that are getting implemented? Maybe. Does the EM look at the backlog of technical debt and prioritize items out of that backlog? Maybe, but if the organization is small enough and the EM is hands-on and smart - they “just go and do things”.
In nearly all the situations I’ve seen, the implementation of processes targeted at legibility were actually optics in disguise. We are now writing user stories because the person who became the CPO wants to establish that practice. We have a this-or-that process because the executive – or the key stakeholder – wants it implemented in a specific way. Or - because they do not care
Drive manually
On the 30th of August, 2000, a train flew out of the tunnel at a station in Paris, and, without stopping, rolled on through into the tunnel. It was clear that the train was speeding, and speeding severely. Inside the tunnel, the train has derailed with the front cab car turning over. Luckily, there were no fatalities. 24 people were injured.
The investigation was able to establish that the train’s speed was above the maximum permitted on that section of track by 20 km/h, if not more. How could this happen, given that the Paris Metro has been equipped with automatic speed control since the early 70s?
Turning your Apple Calendar into a time tracker
In the brave new world of self-employment one thing I found very important is getting a grip on time. In general, this turns out to be the biggest challenge for me personally - not having kids and no longer living with a partner I have way more free time than is customary for a 40+ year old, and it shows. And it is becoming more important to get a good understanding of both where the time gets spent, and how much of that time is billable.
In the past I used to use Noko for time tracking, but I found myself cooling down on it. I didn’t really enjoy having a subscription, the jobs I had to do were very sporadic and I no longer enjoyed using it. I’ve looked at a few time tracking packages but was generally put off by subscriptions, the perpetual “onlineness” of them all, and the fact that they were desperately selling to businesses, not consumers like myself. And – got to be frank about it – I am a sucker for not only local-first apps, but native apps.
And then an idea struck me: I am actually using the standard Apple Calendar, with online sync via iCloud, for my calendar needs. If I could add the entries to the calendar, and then tally them - this would give me a great time tracking solution, with the remaining work being generating the invoice from the tally of hours. And, despite Apple turning macOS into a prison of Duplo bricks year over year, there is still some automation available to make this work. So, shall we?
If you need subdomains: just use subdomains
Eelco recently wrote about using subdomains in Rails, outlining a seemingly neat idea about having them as subdomains in production but using paths in development. It is clever and looks very usable at first sight. It’s also a very bad idea that is likely to get you side effects you really won’t be happy about. I normally don’t do “rebuttal” posts, but in this case — since I have dealt with that problem before — it feels warranted. Without being too lyrical about it, I want to outline why you don’t want to use that approach and propose a couple of alternatives.
So, the proposition is this. In production, your tenants/sites are on subdomains called something like site1.product.com, site2.product.com, and so on. In development, however, you will have http://localhost:3000/site1, http://localhost:3000/site2, and so on. This gives you the following URL structure — quoting Eelco:
- Production: https://api.example.com/v1/users
- Development: http://localhost:3000/api/v1/users
Here is why this is quite a bad idea, in no particular order.
Carried datasets, SQLite and Gaelic heritage
A while ago, Simon Willison expressed the idea that SQLite enables a very neat pattern whereby software can carry its datasets in the form of SQLite databases. Such a database is to be used only to read from, and actually presents a very neat, portable, universal data structure for querying a dataset that would otherwise need to be loaded into memory and structured manually. For dynamic and interpreted languages this is actually even more relevant, because loading a sizeable chunk of data from source code involves running the actual language parser over that dataset. That can be quite wasteful. Recently, I’ve bumped into a number of cases where I could apply that pattern, and the results have been delightful!
The dark art of name segmentation
Name segmentation is used in information systems for comparing, searching, validating and outputting people’s names. Segments are parts of a full name, and have different significance when searching, sorting or comparing. It is a thorny affair because a name can be segmented very differently, depending on the culture. For example, if you take my name from my official documents - YULIAN ALEKSEEVITCH TARKHANOV - it can be segmented in a number of different ways:
{first_name: "YULIAN", patronym: "ALEKSEEVITCH", surname: "TARKHANOV"}{first_name: "YULIAN ALEKSEEVITCH", surname: "TARKHANOV"}{surname: "YULIAN", first_name: "ALEKSEEVITCH TARKHANOV"}{first_name: "ALEKSEEVITCH", title: "YULIAN", surname: "TARKHANOV"}
The third variant is likely in systems which have been created in Japanese or Hungarian cultural tradition. Funnily enough, for a native Russian speaker the “last name then first name” address can not only be incorrect, but is also a known case of use of “kantselarit” (the boasty, inscrutable officalized language) or a way of addressing a pupil at kindergarten or at school, so it’s not only incorrect but can be slightly offensive.
Either way, the segmentation – when done right - should give the following outcomes:
- My name should sort on
TARKHANOVin almost all scenarios - When initials are desired, the name should collapse to
YA TARKHANOV - When just the surname must be extracted, it should deliver
TARKHANOV
And one of the interesting bits of segmentation are compound surnames and surnames containing particles. For example OʼSullivan - like in a video you should really check out can be segmented as follows:
{particle: "O", surname: "SULLIVAN"}{surname: "OʼSULLIVAN"}{surname: "O'SULLIVAN"}- note how the apostrophe has been converted into a single quote!{surname: "OSULLIVAN"}- note how the apostrophe has been removed entirely
This reveals an interesting necessity - when searching for a name, for example, you need to search for a “normalized form” of it. All of the following search queries:
O SullivanSullivanOsullivanOʼsullivan
should return that name, regardless of how it’s been entered into the system. This is decently handled by systems that normalize tokens before at ingest - like Lucene - have sophisticated plug-in approaches for doing this token pre-processing. But we can actually go a bit differently, and not have to introduce ElasticSearch or OpenSearch into our stack at all.
Hexatetrahedral Rails
Software is a creative endeavor and a craft. And like any creative endeavor and any craft, it is subject to fashions. About a decade ago, one of those fashions was Hexagonal Rails largely inspired by the DDD book, but also by the original Hexagonal Architecture work by Dr. Cockburn.
Some of these applications are now up for their Rails upgrade and an “oil change,” and it’s interesting to see them in the wild and how they get perceived through the lens of the years that have gone by since then. I call them “hexatetrahedral Rails applications” - in jest, of course - because they often end up presenting complexities that go beyond the intended benefits, sometimes becoming what I’d describe as complications or even complicationments.
And while I appreciate the good intentions behind this approach, I’ve found myself questioning whether the benefits outweigh the costs in most cases. So I felt that - at the very least - I want to suss out why it is valuable, but also - figure out how I define/detect those apps in the wild, and how to understand their raison d’être well. Not to be snarky - but to look for the nuggets of wisdom in there which can be useful for us, today.
Why can't we just... send an HTML email
A few months ago my partner-in-love-and-in-crime came with a seemingly innocuous request, which went as follows:
We have an event coming up, and I need to send out a press release via email. It’s simple enough - just a couple of images and a few blurbs of text. I can’t seem to be able to make it look good in Gmail nor in Apple Mail. How does one do such a thing?
Now, we computer-savvy household members know darn well that HTML email is, on the list of terrible IT things we have to help others with, right below the “can we get this printer to work?”. It can get… challenging. And yet, given that I have done this “HTML email” thing for a while – this piqued my curiosity.
How hard can it be, thought I, to manually code an HTML email with images - and then use some Advanced Technology™ to turn it into a proper HTML email?
While doing that using current commercial platforms turned out to be very hard indeed - for reasons having nothing to do with technology – I did come to an elegant solution that is usable locally. Exactly what I wanted:
- Layout an HTML email by source editing
- Turn it into an actual email (there is a file format for that!)
- Preview it in Apple Mail (on macOS and an iPhone) and in Gmail (desktop Web and iOS)
- …rinse and repeat until it looks great
The real “aha moment” came when I realized that the tools I needed were already sitting right there in my Rails stack, just waiting to be used in a slightly different way. Premailer, Nokogiri, and the Mail gem - these aren’t exotic dependencies or bleeding-edge libraries. They’re battle-tested, well-documented tools.
Curious where I ended up with that? Read on!
Data over time
Since 2021 I have been working at Cheddar Payments, which is a fledgling fintech startup in the UK. It was a substantial change from WeTransfer in terms of the problem domain, but also scale.
The scale at a B2C fintech is smaller, but the challenges are, in ways, much harder. And the biggest challenge - engineering-wise - is “data over time”. I’ve learned more about data over time than I would like, and it can be useful to share my experience.
GETting conditionally - the bare basics
A while ago, a prominent Vercel employee (two, actually) posted to the tune of:
Developers don’t get CDNs
Exhibit A etc.
It is often that random tweets somehow get me into a frenzy – somebody is wrong on the internet, yet again. But when I gave this a second thought, I figured that… this statement has more merit than I would have wanted it to have.
It has merit because we do not know the very basics of cache control that are necessary (and there are not that many)!
It does not have merit in the sense that force-prefetching all of your includes through Vercel’s magic RSC-combine will not, actually, solve all your problems. They are talking in solutions that they sell, and what they are not emphasizing is that the issue is with the “developer slaps ‘Cache-Control’” part. Moreover: as I will explain, a lot of juice can be squeezed out of you by CDN providers exactly because your cache control is not in order and they offer you tools that kind of “force” your performance back into a survivable state. With some improvement for your users, and to the detriment of your wallet. But first, let’s rewind and see what those CDNs actually do.
CDNs use something called “conditional GET requests”. Conditional GET requests mean: Cache-Control. And even I, in my hubris, haven’t been using it correctly. After reviewing how it worked on a few of my own sites, I have overhauled my uses – and built up a “minimum understanding” of it which has been, to say the least, useful.
So, there it is: the absolute bare minimum of Cache-Control knowledge you may need for a public, mostly-static (CMS-driven, let’s say) website. Strap in, this is going to be wild.
And be mindful of one thing: I do not work for Vercel, CloudFlare, AWS or Fastly. I just like fast websites and I think you deserve to have your website go fast as well.
UI algorithms: a tiny promise queue
I’ve needed this before - a couple of times, just like that other thing. A situation where I am doing uploads using AJAX - or performing some other long-running frontend tasks, and I don’t want to overwhelm the system with all of them running at the same time. These tasks may be, in turn, triggering other tasks… you know the drill. And yet again, the published implementations such as p-queue and promise-queue-plus and the one described in this blog post left me wondering: why do they have to be so big? And do I really have to carry an NPM dependency for something so small?
Streamlining web app development with Zeroconf
The sites which are using Shardine do not only have separate data storage - they all have their own domain names. I frequently need to validate that every site is able to work correctly with the changes I am making. At Cheddar we are also using multiple domains, which is a good security practice due to CORS and CSP. Until recently I didn’t really have a good setup for developing with multiple domains, but that has changed - and the setup I ended up with works really, really well. So, let’s dive in - it could work just as well for you too!
A can of shardines: SQLite multitenancy with Rails
There is a pattern I am very fond of - “one database per tenant” in web applications with multiple, isolated users. Recently, I needed to fix an application I had for a long time where this database-per-tenant multitenancy utterly broke down, because I was doing connection management wrong. Which begat the question: how do you even approach doing it right?
And it turns out I was not alone in this. The most popular gem for multitenancy - Apartment - which I have even used in my failed startup back in the day - has the issue too.
The culprit of does not handle multithreading very well
is actually deeper. Way deeper. Doing runtime-defined multiple databases with Rails has only recently become less haphazard, and there are no tools either via gems or built-in that facilitate these flows. It has also accrued a ton of complexity, and also changes with every major Rails revision.
TL;DR If you need to do database-per-tenant multitenancy with Rails or ActiveRecord right now - grab the middleware from this gist and move on.
If you are curious about the genesis of this solution, strap in - we are going on a tour of a sizeable problem, and of an API of stature - the ActiveRecord connection management. Read on and join me on the ride! Many thanks to Kir Shatrov and Stephen Margheim for their help in this.
Template-Scoped CSS in Rails
Hot on the heels of the previous article I was asked about my idea of having co-located CSS. Now is the time to share, so read on!
Update (2026-02-7)
Most of the points in the article still stand, but with @scope now being baseline you can use use it in addition - or instead - of the nested classes.
A supermarket bag and a truckload of FOMO
The day was nearing to a close. The sun has already set, but that Friday evening in Amsterdam was still warm. Unusually warm, in fact, for those late days in March – as if spring decided to bless my pilgrimage, for that pilgrimage was not jovial.
I was sitting at a ramen joint, sipping on the broth. To my left, a blue, crinkled supermarket shopping bag was sitting solemnly, inconspicuously.
Inside that bag sat a slightly used Mac Studio, which I have just purchased to be able to edit CSS of my own application.
By the time that evening descended upon the south of Amsterdam, I have lost 3 days of my life trying to figure out why I was unable to edit CSS.
But let me rewind a bit.
UI algorithms: a tiny undo stack
I’ve needed this before - a couple of times. Third time I figured I needed something small, nimble - yet complete. And - at the same time - wondering about how to do it in a very simple manner. I think it worked out great, so let’s dig in.
Most UIs will have some form of undo functionality. Now, there are generally two forms of it: undo stacks and version histories. A “version history” is what Photoshop history gives you - the ability to “paint through” to a previous state of the system. You can add five paint strokes, and then reveal a stroke you have made 4 steps back.
Musings on module registration (and why it could be better in Rails)
Having the same architecture problems over and over does give you perspective. We all love making fun of the enterprise FizzBuzz but there are cases where those Factories, Adapters and Facades are genuinely very useful, and so is dependency injection. Since I had to do dependency injection combined with adapters a wee many times now, it seems like a good idea to share my experience.
What I will describe here mostly applies to Ruby, but it mostly applies to the other languages and runtimes too.
The surcharge of big tech
There is a lot of talk that big-tech companies are willing to pay way more, way up north of the market to the local rates. They all seem similar:
- Pre-IPO or public
- Looking for senior software engineers or staff engineers
- Salary brackets never published, and even recruiters stay fairly tight lipped
- So-described “transparent” interview process - usually a marathon of systems design, “culture fit” and leetcode-like excercises
And yet it seems that it is hard for those firms to acquire talent, even though in some cases they are prepared to offer compensation 40% to 50% higher than a standard local development agency would. Why is that?
Well, they know what they are recruiting for. It is a challenging environment, and – despite it sometimes lookign otherwise – they want the people they hire to still be able to perform.
Disownership, pull requests and de-facto architects
A while ago I got really triggered by by the following two tweets - one by Avdi and another by Pete
This essay was on my mind - and lying dormant - for a couple of years, but I think it didnt lose its relevance.
Supercharge SQLite with Ruby functions
An interesting twist in my recent usage of SQLite was the fact that I noticed my research scripts and the database intertwine more. SQLite is unique in that it really lives in-process, unlike standalone database servers. There is a feature to that which does not get used very frequently, but can be indispensable in some situations.
By the way, the talk about the system that made me me to explore SQLite in anger can now be seen here.
Normally it is your Ruby (or Python, or Go, or whatever) program which calls SQLite to make it “do stuff”. Most calls will be mapped to a native call like sqlite3_exec() which will do “SQLite things” and return you a result, converted into data structures accessible to your runtime. But there is another possible direction here - SQLite can actually call your code instead.
Maximum speed SQLite inserts
In my work I tend to reach for SQLite more and more. The type of work I find it useful for most these days is quickly amalgamating, dissecting, collecting and analyzing large data sets. As I have outlined in my Euruko talk on scheduling, a key element of the project was writing a simulator. That simulator outputs metrics - lots and lots of metrics, which resemble what our APM solution collects. Looking at those metrics makes it possible to plot, dissect and examine the performance of various job flows.
You can, of course, store those metrics in plain Ruby objects and then work with them in memory - there is nothing wrong with that. However, I find using SQL vastly superior. And since the simulator only ever runs on one machine, and every session is unique - SQLite is the perfect tool for collecting metrics. Even if it is not a specialized datastore.
One challenge presented itself, though: those metrics get output in very large amounts. Every tick of the simulator can generate thousands of values. Persisting them to SQLite is fast, but with very large amounts that “fast” becomes “not that fast”. I had to go through a number of steps to make these inserts more palatable, which led to a very, very pleasant speed improvement indeed. That seems worth sharing - so strap in and let’s play.
Joke accounts are a bitter necessity
Joke Accounts and the BOFH are Garbage by Aurynn Shaw struck a chord with me back in the day. After all, who wants to exclude people? Who wants to make them feel unwelcome? Having survived some amount of difficult working experiences I have changed my mind on this drastically. The joke accounts are a bitter necessity, and I’ll try to explain why.
Reviving zip_tricks as zip_kit
Well-made software has a lifetime, and the lifetime is finite. However, sometimes software becomes neglected way before its lifetime comes to an end. Not obsoleted, not replaced - just.. neglected. Recently I have decided to resurrect one such piece of software.
See, zip_tricks holds a special place in my heart. It was quite difficult to make, tricky, but exceptionally rewarding. It also went through a number of iterations, and working on it taught me a great lot. How short methods are not always a good thing. How it is important to provide defaults. How over-reliance on teensy-tinesy-objects can make software hard to read and understand (in case of Rubyzip). And how open source might work in a corporate setting.
What follows is the story of how zip_tricks became zip_kit and what I have learned along the way.
Exploring batch caching of trees
From my other posts it might seem that I am a bit of a React hater - not at all. React and related frameworks have introduced a very powerful concept into the web development field - the concept of materialised trees. In fact, we have been dealing with those in Rails for years now as well. Standard Rails rendering has been a cornerstone of dozens of applications to date, and continues to be so. But once you see “trees everywhere” it is hard not to think about optimising using trees. So let me share an idea I’ve had recently which might as well be very neat.
Testing a thousand applications with Flipper
Feature flags are amazing. No, really, did I tell you that feature flags are amazing? They are. But you might be running a thousand applications. When this kind of complexity gets involved you might need to test combinations of feature flags, sometimes - dozens of those combinations. Exhaustive testing to the rescue!
Tool complexity might have a cure: those pesky people who say no
Marco Rogers started a remarkable thread on Mastodon, which absolutely struck it home for me. Teams absolutely do get mired up in complex tooling. They absolutely can be unprepared, and there absolutely is a skew between the newly-minted “frontend” and “backend” ecosystems. I might have a few things to say about this.
Your might be running a thousand applications
Feature flags are awesome. But just like user preferences or settings they have the tendency of turning your application into multiple applications, all embedded in one.
Changing your mind is not my job
There is a popular meme that has been going around for years now, This is in fact close to heart for every passionate technologist. Most of use have either been the guy at the desk, or an innocent passer-by willing to enter the conversation. With fairly expected results.
Versioned business logic with ActiveRecord
Every succesful application evolves. Business logic is often one of the things that evolves the most, but it is customary to have data which changes over time. Sometimes - over months or years. A lot of spots have logic related to “data over time”. For example: you collect payments from users, but some users were not getting charged VAT. Your new users need to get charged VAT, but they will also pay more, but you want to “grandfather” your existing users into a pricing plan where VAT is included in their pricing, so that the amount they pay does not change.
ActiveRecord, by default, is not very conductive to such changes, but I have recently discovered a very nice pattern for adding versioned logic to models.
On the value of interfaces (and when you need one)
It is curious how people tend to bash DDD. I must admit - I never worked in a full-on DDD codebase or on a team that practices it, but looking at the mentioned articles like this one does make me shudder a little. There is little worse than a premature abstraction, and a there is a noticeable jump (or rather: a trough) which goes from abstraction to indirection. I’ve been programming for more than 20 years now - 12 of those professionally (with a little stint in-between) and I also went from obsessing over abstractions to a more, let’s say, “common sense” approach to them. Oddly enough, this is not about OOP for me - it is about modules. And, to an extent, types - but I do believe types and behavior are going to stay connected in meaningful way. Whether you do point.move() or move(point) is not of importance as long as it generalizes over some kind of Movable.
It did take a while for a more digestible take on this to begin to crystallize, so I fugured it could be put on paper.
UI algorithms: drag-reordering
A list where you can reorder items is one of entrenched widgets in UIs. Everyone knows how they are supposed to work, they are cheap to build, intuitive and handy. The problem is that they often get built wrong (not the “just grab Sortable.js and be done with it”-kind-of-wrong, but the “Sortable.js does not provide good user experience”-kind-of-wrong). I’ve built a couple of these for various projects and I believe there is an approach that works fairly nicely. So let’s build us a reorderable list with drag&drop. As usual, we will be doing this laaaive without React and without any libraries.
The unreasonable effectiveness of leaky buckets (and how to make one)
One of the joys of approaching the same problem multiple times is narrowing down on a number of solutions to specific problems which damn work. One of those are idempotency keys - the other are, undoubtedly, rate limiters based on the leaky bucket algorithm. That one algorithm truly blew my mind the first time Wander implemented it back at WeTransfer.
Normally when people start out with rate limiting, a naive implementation would look like this:
WebRequest.create!(at_time: Time.now)
if WebRequest.where(key: request_ip).where("at_time BETWEEN ? AND ?", 1.minute.ago, Time.now).count > rate_limit
raise "Throttled"
else
WebRequest.create!(key: request_ip, at_time: Time.now)
end
This has a number of downsides. For one, it creates an incredible number of database rows - and if you are under a DOS attack it can easily tank your database’ performance this way. Second - there is a time gap between the COUNT query and the INSERT of the current request. If your attacker is aggressive enough, they can overflow your capacity between these two calls. And finally - after your throttling window lapses - you need to delete all those rows, since you sure don’t want to keep storing them forever!
The next step in this type of implementation is usually “rollups”, with their size depending on the throttling window. The idea of the rollups is to store a counter for all requests that occurred within a specific time interval, and then to calculate over the intervals included in the window. For example, with requests during 5 seconds, we could have a counter with a secondly granularity:
if WebRequest.where(key: request_ip).where("second_window BETWEEN ? AND ?", 5.seconds.ago.to_i, Time.now.to_i).sum(:reqs) > rate_limit
raise "Throttled"
else
WebRequest.find_or_create_by(key: request_ip, second_window: Time.now.to_i).increment(:reqs)
end
This also has its downsides. For one, you need to have good granularity counters, meaning that the interval which you count (be it 1 second, 1 day or 1 hour) need to be cohesive with your throttling limit. You can of course choose to use intervals sized to your throttling window and sum up “current and previous”, but even in that case you will need 2 of those:
|••••••• 5s ••T-----|----- 5s -----T•••|
There is also an issue with precision. If you look at the above figure, “window counters” would indicate that your rate limit has been consumed even though looking back 5 seconds from now you are not covering the entire 5 second window looking back, but just a portion of it. So if you sum the counter for the current interval and the last, the sum might be higher than the actual resource use for the last 5 seconds.
As a matter of fact, this is what early version of prorate did.
Two other possible reasons juniors are having it tough on the job market
It has recently become a hot topic that junior developers are having difficulties finding a job, even though the market is very hot at the moment. Market for senior talent is, yes, but for juniors - not so much. As a matter of fact it has been flagged that it is harder than ever for a beginner to start a career in software. Multiple causes have been outlined:
- Companies do not want to invest into talent which is going to demand extreme raises or leave as soon as they make up experience
- Companies assume they are not able to train and teach in a full-remote setting
- Companies assume they need a full-blown training program
I would like to raise two extra topics though, which I haven’t seen mentioned. I might be a minority voice here, but I feel they are relevant and we are not giving them due attention.
We really need to change this.
Actually creating a gem for idempotency keys
I’ve already touched on it a bit in the article about doing the scariest thing first – one of the things we managed to do at WeTransfer before I left was implementing proper idempotency keys for our storage management system (called Storm). The resulting gem is called idempo and you use it about like this:
config.middleware.insert_after Rack::Head, Idempo, backend: Idempo::RedisBackend.new(Redis.new)
It is great and you should try it out. If you are pressed for time, TL;DR: we built a gem for idempotency keys in Rack applications. It was way harder than we expected, and we could not find an existing one. As a community we do not publish enough details about how software gets designed, which makes it less likely that our software will be found and used. I don’t want this to happen to idempo. Making a gem which does a seemingly tiny thing can be devilishly complex, and switchable implementations for things are actually useful.
Disclaimer: consider all code here to be pseudocode. For actual working versions of the same check out the code in idempo itself.
Why did we even need it?
To recap: idempotency keys allow you to reject double requests to modify the same resource (or to apply the same modification to the same resource), and they map pretty nicely both to REST HTTP endpoints and to RPC endpoints. Normally idempotency keys are implemented using a header. For a good exposition on idempotency keys, check out the two articles by Brandur Leach here - the first one gives a nice introduction, and the second one gives a much more actionable set of guidelines for implementing one.
The point where we realised that we will need idempotency keys in the first place came about when we decided to let other teams use a JavaScript module that we would provide. The module - and the upload protocol WeTransfer uses - is peculiar in that it has quite a bit of implicit state. Multiple requests are necessary, and they need to be synchronised somewhat carefully. Requests should be retried, because we were already using a lot of autoscaling - so a server could end up dying during a request. Yet some of the operations we let our JS client perform (such as creating a new transfer) must be atomic - you can only create a transfer once, and there is some bookkeeping involved when doing that. The transfer is going to have a pre-assigned ID, and if the client attempts to create a transfer and then does not register properly that the transfer got created the ID will end up taken. This bookkeeping touches the database, and thus creates database load. Also, the output of those operations can be cached for some time. In the past, we had situations where an uploader would end up in an endless loop (due to problems with retry logic for example) and would hit the same endpoint, near-endlessly, and very frequently. If we had an idempotency key system we could significantly reduce the impact this had on our systems – and avoid a number of production incidents. So with the new JS client we wanted to make it support an idempotency key for the entire upload process for your transfer, and we wanted to have this idempotency key be transparently used on the server.
As a matter of fact, also our iOS app ended up implementing idempotency keys in the same way - and with the same benefits.
Surprisingly to us, while Ilja Eftimov has made a good write up about idempotency keys and made a demo of an implementation in this article we were surprised to find no proper gems for idempotency keys existed, which we could pick off the shelf. So some brainstorming and a little pondering later we decided that we had to make one, albeit only for our storage manager system. It is not that Ilja’s code is bad – it just omits a few interesting side-effects which might be more frequent than we could think of initially.
This article is long, and there are a few things I want to touch on here.
Before we move any further: idempo came about with great help from Lorenzo Grandi and Pablo Crivella, sending my hugs to both. Lorenzo is also in the fabulous new Honeypot documentary that you can find here.
The value of not having to be right
In software we pride ourselves in being “data-informed”, “metrics driven”, and “formally proven” is the highest praise. Few things feel as satisfying as being actually right, with no shadow of a doubt and no way of escape for our opponents. Being tech people, we cling to this idea that “the more correct” idea, or the one which is “objectively right”, should win.
Now, do not underestimate this:
As long as all we have is opinions, mine is the best.
which is “one way to do it” – specifically, “a way” to do it if the team is comprised of jerks. But believe it or not - most teams are composed of decent humans who genuinely want to do good by each other.
Art, science, taste and "clean code"
Science establishes concepts that describe nature, and is often able to signal binary answers to questions. “Can acceleration be non-0 when velocity is 0?” “What is the circumference of a circle?” “How many chromosomes does a fruit fly genome contain?”
Art, unlike science, speaks to our emotion. Great art is great exactly because - in addition to execution - it stimulates us to imagine something which makes us feel in a certain way. It is about communicating emotion.
There is a ton of talk about how “bikeshedding details” is “sophistry”, “you should not care that much”, “style reviews create opportunities for abuse” and the like. But we are, as a community, slowly moving towards optimising for two things, and two things alone:
- Making all changes we do measurable improvements. Either using objective or fake metrics which will somehow demonstrate that “we were right” or “we were wrong”
- Making nobody feel bad, ever
When we optimize in that direction, we tend to dismiss (or even discourage) “taste”, because of course it is personal, it is subjective, and it can be imposed by someone in position of authority. What we do skimp on in the process, is that “bikeshedding” design decisions - and code! - bringing back taste thus - can produce a solution which is not only “nicer”, or “pleases the loudest senior person on the team the most”. There are things we can debate in that domain, and they are all of differing orders:
- Not code formatting (just install an automatic formatter for this and move on)
- Size of modules / functions
- Granularity of modules / functions
- Verbosity / DRYness of tests
- Quality of encapsulation
While the things above are not quanitifiable, the paradox is that their outcomes can be, or at the very list they can be qualifiable. They are important and if you give them some TLC you are going to get reductions in your cost of ownership down the line.
The good questions for bikeshedding
Here are those, and I was incredibly lucky to see more than a few times when prioritizing them in bikeshedding discussions led to meaningful, useful outcomes. I like to formulate them as questions - because barking orders at each other is exactly what creates the toxic environments we overcorrected from. Let’s walk through those questions:
- How long will it take a person who never worked on your module before to read your test when there is a problem? What will be the hurdles they are going to likely encounter? What will be the cost of unpacking the abstractions you have used?
- What could we change so that the addition of your module, in total, allows us to have less software?
- Is there something in your change that is going to be difficult to understand for a person 1 level below you in seniority? 2 levels? 3 levels?
- If this codebase already contains 3 places where a similar module/change has been added, does your 4th change warrant doing in a different style? Are you committing for the other 3 too or are you just being a passenger for this one feature?
- What will be the cost of removing this module you are adding? Can we reduce the necessary churn it to removing 2 files (module + module test) from the code repository? and have nothing break?
- How many jumps from module to module (or function to function) will someone have to do to understand a specific flow in its entirety?
- Does the API surface of this module map well onto the underlying system one level down that it is driving?
Case study: if you ever wondered why so many have problems with Redux, try to size the codebases using Redux that you have seen against this list of questions:
- How hard will it be to remove this reducer+actions+dispatch functions if we want to get rid of them?
- How much indirection has to be followed to read this UX flow start-to-finish?
- Is the use of Redux state coherent with the use of local state?
Questions map to costs
In effect, when we bikeshed over these questions, we optimize for two very specific costs of software to us:
- Cost of reading and understanding
- Cost of removal/rework
And these costs are also to the business, because they will be very apparent when features have to change, or when the teams need to scale. Let’s deal with those in order.
Cost of reading and understanding
The first one is essential, and also something that is not well covered either in vocational study (bootcamps) or in CS curricula - we spend way, way more time reading and understanding existing code than we do creating new code. We absolutely do not pay enough attention to making our code easier to understand. And making code easier to read and understand is directly coupled to those pesky “taste” and “style” issues we so so forbid each other from discussing. Just a small sampling of those:
- Longer identifiers (
max_widthinstead ofmw) - Identifiers hinting behavior or type (
maybe_userfor a nullable,body_strfor a string as opposed to “body abstraction from one of the libraries we use”) - Use of keyword arguments/named arguments over positional arguments (
insert(at: pos, item: it)overinsert(it, pos) - Use of standard language constructs over framework constructs (
prependoverActiveSupport::Concern) - Comments explaining any non-obvious behavior (
# S3 multipart part numbers are 1-based) - Metaprogramming / macro output examples next to macro code
And these questions - if you look close enough - are not of the variety “I like it more” - they are of the variety “we are not doing our job well because it will be harder for a new person to understand this system”.
If we follow the now-mainstream “make everyone feel nice” ideology, we are invariably getting to a situation where asking for these affordances becomes a social misstep.
Moreover: modern teams with high-paced delivery operate via very, very opaque socio-political streams. With how hard it is to “perform” in a modern enterprise getting the “code” right is actually the easy part! There is a whole battery of adverse effects of the modern workplace which are going to make it impossible for the same person to “own” the same module for any meaningful amount of time. But exactly because of these difficulties we should pay more attention. Even if the model of operation is “commit the module, have people get their promotion, have a reorg, be moved to the next feature” - someone is going to inherit this code and highly likely will have to deal with it in some way. Someone will carry your can. The faster our org chart iteration, the more important it is to make your material discoverable, readable, clear.
Cost of removal/rework
This is something we do not think about much at all, because “removing a piece of software never got anyone promoted” - just like “nobody got fired for choosing Java”. But it does provide tangible benefits, and does make iteration easier!
For example, in the last project I have worked on, we implemented idempotency keys. Despite two great articles on the topic existing - one from Brandur and another from Ilja - there was no good module for idempotency keys we could use off-the-shelf, so we had to roll our own. We had to go through 2 throwaway implementations before we found one that became idempo
This would have been considerably harder to do if our idempotency keys were managed from the various applications we have inside of our Rack wrapper application, and became very easy with just one line of middleware. To swapover from one implementation to another, we had to change 2 lines in our codebase. To remove an iteration which didn’t work, we had to delete 2 files and 2 directories (since we used modules, everything could be removed in one go).
Same for things where - if you squint well enough - you say “if we were aiming for the microservice architecture this module would be a service”. Why not make it a single module with one function? If the fashion for microservices stays, and the product you are working on becomes more successful, replacing a local function call with an RPC call will be easy. Going in the opposite direction will be much harder because the cost of removal of a microservice is higher (remember the bit about “delete 2 files”).
See also - Write code that is easy to delete, not easy to extend.
Good kind of bikeshedding is bikeshedding which optimizes for better communication and easy removal. Let me leave you with this quote by @zverok which should be printed on banners and hung on walls across all the offices where software gets worked on:
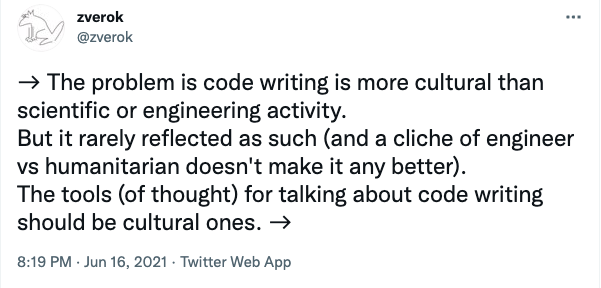
Truly the whole thread is magnificient - find it here
Thus: the bike shed should be green, because most bikesheds in our neighbourhood are green and because we regularly hire people who have never in their life seen a bike shed. And it must use keyword arguments. No argument about it.
For another great and considerate take on the topic - see Why We Argue: Style by Sandi Metz.
Do the scariest thing first
I know the pieces fit, cause I watched them fall apart
Kir recently wrote about fragmented prototyping which struck a nerve. I use a very similar approach for gnarly engineering and system design problems, so figured I could share while we are at it. I call it the maximum pain upfront approach. Another name could be do the thing that scares you the most first.
It goes roughly like this. When you need to design a system, make an inventory of the tasks/challenges you expect and make a list of them. Preferably list out all of them, in detail. Then look at that list, and find the thing you know the least about - or a thing that scares you the most. Then try to “run around” your system and design the least possible amount of “glue” around the piece you are worried about. It doesn’t have to be perfect, “just enough” is enough. Make your system do something sensible, provide just that little bit of output which proves your system is sane and can roughly do what it is supposed to do. This will be your “skeleton”.
Then comes the “maximum fear” part. Laser-focus on the part of the system which scares you the most. Something you never done before. Something you do not know the constraints of. Something that requires you going 2-3 levels “down” from what you normally consider comfortable. I’ll give a few examples from my experience where I hit those “maximum fear” aspects:
- In zip_tricks the part I was completely lost about was parallel compression. In retrospect it wasn’t that necessary because we ended up not using it (the cost of speculatively compressing all of the uploaded data proved too great when more than 80% uses lossy compression formats, and will thus not compress well)
- In SyLens it was matrix transforms
- In the download server, Ruby memory consumption was the item that scared me the most - especially because initial experiments were not encouraging at all
- In idempo the atomicity guarantees and data races were legitimately scaring me quite a bit
Here is how to recognise one:
- You never did anything like this before.
- You vaguely know that the thing will have behavior you do not completely understand - like race conditions, or numeric precision issues
- You are unable to visualise the code / design which will carry the feature ahead of time
- You know that the problem touches a theory topic you are unfamiliar with, and it will require you to upskill
- You try to search for readymade solutions, and they are vaguely close – but don’t look like “closed form” solutions, or you have doubts you wil be able to use them in your case
In all of these situations, I went about it roughly the same:
- Set up the “skeleton”, or “harness”, which will run the code that scares you the most - it can either be a minimum possible implementation of the “system around” that you are building, or just a test runner. Make sure it works first, make it accept input and provide some output! These “scary problems” often cause you to backtrack - or, in extreme cases, will need the work abandoned! Be prepared for this and do not get caught with a blank sheet of paper. Having a “skeleton” will allow you some holdfast to come back to if you get lost in the woods
- Try any approaches that could work. Test-driven might work well if you can isolate the part of the system well. Metrics work great - profile and measure and try to compare various solutions to give you perspective. Use visualisations, sketches, Matlab plots, Jupyter notebooks, Excel - anything that gets you closer to a solution is fair game! Doesn’t have to be in the target language even (sometimes).
- Time-box your effort. This is important! Scary problems are nerdsnipe nirvana. You can become so consumed that you will lose track of all the other work that needs to be done. If you do not have a time limit a scary problem can consume you for months and you won’t even notice.
In my previous work I had a few jobs where I would laser-focus on a particular part of the job, partially because it was the chunk I was unsure about the most. I would then spend most of my allotted time – without the “skeleton” setup in place – on “nailing” the part I was fearful of. As the time ran out, I would en up in a situation where only about 20% of the “scary thing” was done, but there was nothing besides it. No skeleton, no reversion strategy and no “big strokes” version to backtrack to. This was very embarrassing and painful for the clients/stakeholders too!
So, imagine you end up with a problem similar to what Kir encountered: “Make programming language X do Y bytes per second over interface Z.” You have never done this before, you know that this requires detail work and it might yield a negative outcome (“it is not possible to make this thing do that”). Time-box for it! Allow yourself a day or two just for that problem, and have a wrapper in place. If you fail, you can backtrack to the wrapper and begin again, or replace your yet-missing implementation with a shim of some kind. It will also give you space to try again later. On some of these problems, I had to make 2, 3 or even 4 attempts before the final solution emerged.
A few caveats are in order of course.
- When you see a problem like this - think about bypassing it outright. For example: you know that DynamoDB has write and read quotas, and you are afraid of hitting them. Think about whether your project needs DynamoDB to begin with. Could you do without it? Maybe using a datastore with different guarantees and tradeoffs can get you to the end solution faster, and will allow you to skip the problem?
- What will you do if you are unable to solve the problem? Have a plan B. If your system is moot without the scary component: congratulations, you have potentially blocked yourself.
- Have a buddy. You will, after some time in the field, have a list of names you could scroll through – of people who “know a lot about X”. Ask the person who knows the most about the part that scares you so much, maybe not immediately but it helps to have them in the back of your mind. This is where bona-fide networking becomes essential.
- This is not necessary everywhere. Sometimes there is no “scary component”, there is just… grind. Time pressure, temperamental client/stakeholder, shitty deployments, that sort of thing. Know to recognise and manage accordingly. Especially when we get bored out of our mind, we tend to create complicated contraptions, fight through their complexities and then admire the end result, while they should not have been applied in the project to begin with.
- The technique is usable when you can recognise the scary problem. It is going to be much, much harder for a junior to recognise those – and they are different for each and every person (there is an intersection of your skillset and problems you can attack). A crucial task for a mentor is to find those scary parts ahead of time, and either steer the mentee around them or try to attack them ahead of time to give the mentee some cover.
- And obviously: the bigger the team, the easier it would be to find people familiar with the topic of the scary problem. They might be able to crack it for you quickly – so divide work if you can. If your team can have good, hot, frank conversations about areas of expertise: you are in luck.
- It could be that the true challenge lies where you did not expect it instead. By investing time in the scariest thing you wil rob yourself of time that you could have used for discovering the “unknowns” you didn’t even think existed, and they would turn out even scarier. So again: the “scariest thing upfront” technique I would recommend to experienced users.
This approach has saved my bacon quite a few times. Use with moderation, and may you always succeed.
You must be this tall to do the five whys
There recently was an essay by Gergely about incident response, and a related example of “The 5 Whys” questions, which has been mentioned as a good way to do incident retrospectives.
I am not a fan of the “5 whys” approach, because I came to believe there is a problem with it in that it overfocuses on one particular path. With just 5 of the “whys” there is only so much you can express that only touches “abstract group output” or “technology”, without getting into the all-touchy-feely, people side of the issue. “The 5 whys” is by far not deep (and not wide) enough to even start approaching these.
Let’s set the scene: there was an outage due to a bug, and teams are doing a retrospective which focuses on how mitigation was handled (not the bug that caused the incident). We “chop scope” here to maintain focus. Imagine we start with the following “5 whys”:
- Why was the site down for customers? Because there was a small bug. It was easy to fix but deploying the fix-forward took too long.
- Why did it take so long to release the fix? Because half of the time was spent waiting for CI to pass, and the other half for the fleet to be rotated
- Why did it take so long for CI to pass? Because our UI tests are slow and flaky
- Why did it take so long to rotate the fleet? Because we do not have sufficient instances to double capacity during release, and the deployed artifact is a very large image
- Why do we need immutable infrastructure and large images? Because the industry does not provide a readymade path for “slim overlay” artifacts and because immutable infrastructure has other benefits we found more important than rapid releases
Now imagine a slightly different list of “whys”, asked with a bit more tenacity:
- Why was the site down for customers? Because there was a small bug. It was easy to fix but deploying the fix-forward took too long.
- Why did it take so long to release the fix-forward instead of rolling back? Because to roll back you need to have adequate stored artifacts and a UI that operators can use in time of duress
- Why don’t we have such a UI? Because the deployment control is run by a different team than the operators managing incidents
- Why can’t operators create their own tools for deployment control? Because they are going to use tools not familiar to the team managing infrastructure, and that team wants to own and control all of those tools
- Why does the team managing infrastructure decide on choice of tools for building deployment control? Because they have their own deployment control scheduled for Q4 of next year.
See - there is already a plot emerging. We have two teams, the incentives of those teams are misaligned, therefore there are no rollbacks and every fix must be a fix-forward, which must trigger the long UI testing path. Oh, and apparently operators of the service do not like the deployment tooling. But we are doing an exercise here, let’s push it a notch and get edgier still. Remember, this page is a “lab” - nobody is going to get hurt:
- Why was the site down for customers? Because there was a small bug. It was easy to fix but deploying the fix-forward took too long.
- Why did it take so long to release the fix-forward instead of rolling back? Because there was no interface available to perform rollbacks 2b. Why was there no interface to perform rollbacks? Because 6 people tried to set up a deployment control UI which would allow for rollbacks, but all of them were denied the opportunity “to not stir waters”
- Why, if the need to have deployment control was so apparent, did we discourage 6 people from solving that problem? Because we didn’t want to make the team maintaining infrastructure upset
- Why were we so scared of making them upset? Because a person on that team is known to be volatile, and could have deleted the production database and could create great risks for the business
- Why do we have a team which poses such a business risk? Because upsetting them could trigger actions that would severely damage production systems, and we lack proper safeguards to prevent this.
See, this gets hot right there. More importantly, there were multiple questions regarding the applicability of “The 5 Whys” in a very interesting light: “who is interested in uncovering the truth” - and, more importantly, the “truths” to uncover differ depending on who is digging.
People usually prefer to feel good, and usually do not like being blamed or pinpointed for things. And the desire for incident retrospectives is a good one - it is to figure out the reason for the most painful things in the incident, and figuring out how, in the future, something like this can be prevented. The challenge lies in the fact that there are multiple truths. All of the three variants of the conversation above present things which are true, but groups will be motivated to steer towards the “first” variant, where there is no blame, no statement of potential unintended consequences, weakness or fear, and questions which are on many people’s minds get avoided. This first variant is not intrinsically “better” than the rest, and in terms of answering the question about recovery and improving the situation it might provide hints how the organisation could proceed.
But from the perspective of “uncovering the truth” - which, I would concur, is a very noble objective which should not be discarded - you will be getting much more bang for your buck with the “third variant”, where you steer directly into the touchy-feely problems. The issues like the one here very often are issues of dysfunctions within (or between) teams, and they will often be the hardest to address. Fixing them will have an incredible rejuvenating effect as well.
The challenge is twofold: first, 5 is too little. When you are in a situation of extreme stress you do need to be able to get by with “just 5” I imagine, but in a more relaxed case (and we are in this situation mostly - we are just running websites, come on!) - all of the three variants above could be explored and discussed. All of the three variants provide facets of truth, and if a collective is truly mature they will be able to explore more of these facets without becoming defensive or hostile. There are tools for this! Non-violent communication is just one that comes to mind.
It is not a linked list, it is a tree - and doing a good traversal of that tree can, indeed, “uncover” truth that you do want to know - or, often, that is long overdue being put on paper or spoken out in public. This is where emotional safety, trust and vulnerability are paramount. Of course you could say this is a conversation path only those in positions of relative safety and privilege can permit themselves to have. And yet: ponder the idea that you could get to a mode of communication where you could unwind things to the level of “stop short of societal problems at large” instead of “stop short of mentioning anything related to how people behave badly with one another”.
Compare the potential outcomes of this particular session:
- If we use the first variant, likely we will decide to “add button to bypass UI tests”. This is a plausible approach, only it introduces its own decision trees later:
- How do we know our UI doesn’t have regressions?
- Who decides which of the builds with skipped UI tests is “good enough”?
- There is still no rollback…
- A likely consequence of the tradeoff will be “We have deployed a version with broken UI to mitigate an unrelated bug”
- If we use the last variant:
- We uncover a great risk to the business and we can look for reconciliation or rupture to mitigate that risk
- We can start work on deployment tooling
- We ruin silos teams have worked themselves into
- We likely don’t have to skimp on UI testing because we will be able to roll back to a “known good” version
Only you must be this tall. The very hot, intense “5 Whys” bursts could work - between equal co-founder peers, and in situations of extremely high levels of trust. That is not a luxury afforded to everybody.
Or you should skip the 5 whys alltogether and go for contributing factor analysis instead. In fact, this is the methodology I would recommend most teams of medium size and up.
P.S. As this article was being finished, news finally came in that the industry we must learn from - aviation - is learning its lesson, as Boeing’s chief technical pilot is indicted for fraud. I do not hold my hopes for higher Boeing brass getting actual accountability, but one can dream.
Why we can't have proper mentorship
This article really made me jump out of my seat. The topic of mentoring isn’t covered properly in our industry, and after having some experience in mentoring and being a mentee – both in software and elsewhere – I believe it has to do with the fact that our approach is deeply flawed to begin with.
Over the years I had about 6 mentors (or coaches, if you will), and have myself mentored about 10 people. Only once did it end in something completely unintended or dramatic, and when I was the mentee only once did it not do something good. Two of my mentors have left me worse off than where they started - one was a legitimate asshole (these people do exist, I was lucky to only have one as mentor) yet the apprenticeship proved very useful for me later. And on the level of craft there was a lot of stuff which was superbly useful. The other mentor was just unfit to lead people in this manner, and this happens too. It seems this is something our industry is overprotective for, but in my case what would have worked much better were to simply not give this person the task of mentorship – they were (and still are) excellent at their other tasks. In creativity, in execution, in precision and perseverance - just not in training.
Let’s look at how mentoring used to work in crafts, and still works in other industries (other than software) - at least to a large extend. When you would join a workshop you would become an apprentice, and there would be a more senior craftsperson assigned to mentor you. Often it would be the shop owner, sometimes it would be someone akin to today’s middle manager. In a design firm it could be one of the art directors, or a senior designer you would be “assigned” to. Most often they would be the person picking projects you would work on and would be able to pick projects which would be good for you to build up skill. Could those be the bad, boring, slog projects - could it be abuse? Of course it could, because there are risks in all things. But the mentor – a good mentor – would have to The mentor must continuously work on instilling good taste and proficiency in the mentee. This is not possible to achieve in a matrix organisation.
Multiple desires (or should I say - fashions) of our industry are extremely at odds with providing good mentorship.
- We assume engineering managers may not code since they are oh-so-busy managing people. But a mentor must assume some management duties with the mentee to succeed. Barber paradox.
- We assume the mentor must have zero imperative control over the work of the mentee, because what if the mentor turns out to be a terrible privileged abusive brute? We assume people enter mentoring for some nefarious reasons, and protecting the mentee from the mentor is paramount. But an essential part of mentoring - instilling the proper taste and work approaches – is impossible if, should things come to a head, the mentor is not permitted to steer execution.
- We assume the mentor must be from a different team “to foster cross-team collaboration”. But this will routinely create situations where a mentor sees that the mentee is working on a useless, potentially even harmful project. Tthat project has been imposed by the mentee’s actual manager, in a wrong setting, with wrong outcomes (like a throw-away web application, which will demonstrate to the mentee that their work is worthless - only the actual manager does not realise it). Yet the mentee can only do that project – while the proper answer for the growth of the mentee at that stage is to be able to say “No, I am not doing this project”.
For the sake of being constructive, let’s list the points: things I have observed which make mentorships succeed. For both participants:
- The mentor has some control of the scope/goals/implementation of the project the mentee works on. The mentor must be somewhat of a manager of the mentee, because otherwise they are not a mentor - they are a “buddy”. This implies that they should be on the same team, or within the same vertical in the organization. “Matrix mentorship” is flawed.
- The mentor is able to shoulder the mentee if they stumble during execution and take the project over. This is not a normal procedure, but it should be available to the mentee – they must be sure someone (in this case the mentor) has their back
- The mentor must be permitted to make last-minute finishing alterations and not be punished for it. Again - this is an escape hatch, to be used at last resort. But it must be available.
- The mentee and mentor must have a clear understanding for the cases where the mentor imposes their taste choices on the mentee. It is often possible that the mentee will not yet be able to understand why these choices get made this way, and it is a sick approach to label this as “dictate” or “abuse”. This is not how crafts mentorship works.
- The mentee has a “tie-breaker” available to them so that they can indicate if the relationship is not working, flag potential issues, or call for help.
The software engineering world should reconsider its attempts to build its own, “hands off” approach to mentoring and rediscover the way mentorship really works. Then we might succeed.
There is no "Heroku, but internal"
A few times a year it seems there are lamentations that “a lot of companies want something like Heroku, but on their internal infrastructure”. Kubernetes does provide something vaguely similar, but apparently isn’t there as far as features go. And time and time again there is this assumption that “if only we had internal Heroku” the amount of tantalizing choices that development teams have to make would be less, deployment would be easier, and everybody would be happier for it.
The fundamental misconception about it is the angle of motivation and control. I don’t believe that “if someone needed Heroku but internal it would have already existed”. As far as I am concerned, something similar was attempted (and I regret I never got to try it out) - it was Skyliner and I have no doubt that a system like that could be developed and marketed. The problem is the one of market. Let me explain.
Some thoughts on streaming responses
Simon Willison has recently touched on the topic of streaming responses - for him it is in Python, and he was collecting experiences people have had for serving them.
I’ve done a lion’s share of streaming from Ruby so far, and I believe at the moment WeTransfer is running one of the largest Ruby streaming applications - our download servers. Since a lot of questions rose up I think I will cover them in order, and maybe I could share my perspective on how we deal with certain issues which arise in this configuration.
Piggybacking on the interface of the server
My former colleague Wander has covered this in more detail for Ruby, but basically - your webserver integration API of choice - be it FastCGI, WSGI, Rack or Go’s responseWriter - will present you with a certain API for writing output into the socket of the connected user. These APIs can be “pull” or “push”. A “push” API allows you to write into the socket, and a “pull” API takes data from you and does something with it. The Rack API (which is the basic stepping stone for most Ruby streaming services) is of the “pull” variety - you give Rack an object which responds to each, and that method has to yield the strings to be written into the socket, succesively.
body = Enumerator.new do |yielder|
yielder.yield "First chunk"
sleep 5
yielder.yield "Second chunk"
end
[200, {}, body]
If you want more performance, you are likely to switch to something called a Rack hijack API which allows you to use the “push” model:
env['rack.hijack'] = ->(io) {
io.write "First chunk"
sleep 5
io.write "Second chunk"
}
Other languages and runtimes will do it in a similar way. So that part is fairly straightforward. You do need to pay attention that between writing those chunks you can somehow yield control to other threads/tasks in your application (so it is really a good idea to dust off asyncio), or just use a runtime which does this for you – like Go or Crystal.
Restarting servers (deployment of new versions)
This is indeed a tricky aspect of these long-running responses. You can’t “just” quickly wait for all connections to finish and restart your server, or decomission your pod/machine/instance and replace it with another. Instead, you are going to be using a process called “draining” - you remove your machine from the load balancer so that it won’t be receiving new connections. Then you use some form of monitoring - like Puma stats - to figure out when your connection count has dropped to zero. Once it did - you can shutdown the server. In practice this means that when you want to deploy a new version of the software you will either end up with a temporary drop of capacity of 1 unit (when you wait for an instance to drain and then start a new one instead), or with a temporary overcapacity of 1 unit (if you start a new instance immediately).
This is somewhat tangential, but a lot of the runtimes we currently use are perfectly capable of “live reloading” - give or take a number of complexities that come along with it. “A Pipeline Made Of Airbags” covers it very well - basically, for a number of tasks we would be better off live-reloading our applications “in situ”, exactly because one of the benefits would be to preserve the current tasks which are servicing connections. We have given this away for the sake of immutable infrastructure, which does give advantages - but if you intend to do those streaming responses you might want to consider live reloading / hot swapping, especially if your server fleet is small.
If you want to do it, Puma - for one - allows you to do a “hot restart” which will drain the running worker processes but spawn new ones.
At WeTransfer, the way we do it is fleetwide draining - we start a draining script on the machines, wait for the connections to drain (bleed off) and then update the code on the machines, starting the new version of the code right after.
There are ways to pass a file descriptor (socket) from one UNIX process to another, effectively transferring a user connection from your old application code to the new one - but these are very esoteric and there is plenty that can go wrong in flight, haven’t heard of these being used much.
How to return errors
Basically - you can’t because the HTTP protocol doesn’t provide for it. Once you have shipped your headers you do not have the option of telling the client what exactly has gone wrong, short of closing the socket forcibly. Luckily most browsers will at least know that you have terminated your output prematurely and will alert the user accordingly. If you are using a “sized” response (which has a Content-Length header) then every HTTP client will raise an error to the user that the response hasn’t been received in full. If you are using the chunked encoding instead - the client will also know that something has gone wrong and won’t consider the response valid, but you can’t tell the client what exactly happened. You could potentially use HTTP/2 trailers for the error message but I doubt any HTTP clients support it.
What you can do is use some kind of error tracking on your server side of things (something like Appsignal or Sentry) and at least register the error there.
Resumable downloads
Tricky but doable given (strict and often unstatisfiable!) preconditions. The problem is essentially one of random access to a byte blob. And actually consists of several problems! Let’s cover them in order.
Idempotent input
You want your returned resource to be the same on all requests, or - alternatively - you need the response not to change between resumptions. It heavily depends on what you are doing, but most - say - SQL queries are not going to be idempotent if your database accepts writes between requests to your report. And you do not have to produce a “baked” response upfront and then serve it piece by piece - but you must be able to reliably reproduce this response based on a frozen bit of input, or - at least - reproduce it’s chunk which the Range header is asking for.
If you can do that - produce a “frozen” bit of state from which you can (via some transformation) obtain a byte-addressable resource - you need to make sure the libraries you use to transform that response will produce identical output. Imagine you have a pipeline like this which produces certain output:
[ SQL resultset ] --> [ CSV writer ] --> [ Client ]
Here, your SQL query and its parameters must be “fixed” and idempotent - so no functions like NOW() should be used. The dataset it queries must, again, be “frozen” and should not change between requests to the resource. Interestingly, Datasette which Simon built is a great example of such a frozen dataset server, so this applies very well here!
If you are using pagination, the requirement stops here - you just need to make sure your paginated URLs return the same results, always. But if you want to provide Range access (random access within a byte blob) - there is another twist.
Random access
The query output goes into a CSV output generator. Now, if all the columns are of fixed and known width (byte size) - which can be achieved by padding them, for example - you can use some offset calculations to know how large one row of your returned dataset is going to be. Based on that, when there is a request incoming, you can “skip” a certain number of rows and generate only the output which is required. However, this means that the version of your CSV library - as well as the version of the algorithm you use to generate your CSV rows (if you are using custom padding for example) – must stay the same. This is why Range requests always use an ETag.
To provide random access you first need to know how large your entire HTTP resource would be. If you are doing output of variable-size chunks - for example, rows in a CSV without padding it with spaces - you are going to have some trouble, because you do not have a way to precompute the size of your output short of pregenerating your entire response first. Which, if you do it that way, is easier just to dump onto some cloud storage and serve it via redirect from there! But: if you are feeling advantegous and your dataset is of known size and has known, sizeable chunks - you can “pre-size” your response. For example, imagine you are serving 12 million samples of a 3D point in space, and it consists of 3 floating point numbers which you know are all within +- 10. You can use a fixed decimal output and you use up to 5 digits for precision. You can then size your response:
def size_response(num_samples)
header_size = "x,y,z\n".bytesize
single_sample_size = " 0.00000, 0.00000, 0.00000\n".bytesize
header_size + (single_sample_size * num_samples)
end
Note how we strategically pad the zeroes with a space - this is what we are going to use for the minus sign if we encounter negative values. Based on a computation like this you can output an accurate Content-Length header - and this gets you closer to supporting Range headers too.
To have those, we allow the user to supply a Range header to us and only return the bytes of the response covered by that header. We can totally do that as long as we can locate the bit of input which will produces the desired piece of output, and pad for the formatting/transformation. Imagine the user requests the following chunk of our hypothetical “3D point” samples (this would be Range: bytes=8-50):
x,y,z
0.0[0000, 0.00000, 0.00000
0.78211,-0.29090, ]0.29311
Based on the function we had earlier we can try to locate which rows we need to output:
offset_of_first_row = "x,y,z\n".bytesize
row_size = " 0.00000, 0.00000, 0.00000\n".bytesize
first_covered_row = (byte_range_start - offset_of_first_row) / row_size # Assuming int division rounding down
last_covered_row = (byte_range_end - offset_of_first_row) / row_size # Assuming int division rounding down
If our input dataset supports cursors we can then use some black magic to materialize only those rows into the response. We might also need to chop off the first 3 bytes of the first output row, and 7 bytes off the end.
All of the above seems pretty convoluted, and it is - but in practice it can be done if truly necessary. Another approach which can be used for both pre-sizing and random access is using some kind of an “segment manifest” - a list of “segments” which compose your response. Both Google’s download servers and WeTransfer download servers do compose a kind of a sequence. We use an internal format called a “manifest”, which looks roughly like this:
{
"segments": [
{"upstream_http_segment_url": "http://some-upstream/blob.bin", "bytesize": 90219},
{"binary_segment_base64": "OnNtYWxsIGhlYWRlcjo=", "bytesize": 14}
]
}
This enables us to compute the size of the resource (by summing up bytesize values of all the objects in the manifest), but also to provide random access by finding objects which are covered by the requested Range. For example, this is the way we do it for ZIP files - while the “metadata” parts of the ZIPs are pregenerated as byte blobs - and stored in those Base64 segments - the included data blobs are streamed through from cloud storage. We can’t reliably generate pieces of ZIP headers but it’s not really necessary - these chunks are “pre-rendered” and available within that segment map, and our library trims off the excess bytes off those chunks if needed.
I know that flussonic and other video streaming servers use a similar approach. Go includes some builtin libraries for that (sizedReaderAt) and the like. The approach with pre-rendering this segment map also means that the output in it will have been generated by a single code deployment of our ZIP library and will be consistent.
When you have a segment map like this, you can use either the serveContent from Go standard library or something like interval_response in Ruby to address these segments using HTTP Range requests - the latter will give you the ranges within your segments too. I’ve covered the technique in this article in more detail.
Some painkillers
If you have random access to files (using the aforementioned interval_response say) but those files would be huge, you can instead generate multiple smaller files and use a segment manifest to allow your application to just grab a few of them. For example, you can provide random access to a very large (arbitrarily large!) collated log file, which actually consistes of many smaller log files, served in sequence. Then you can serve only the pieces of files used by the request:
for_segment_requested do |segment, range_in_segment|
segment.seek(range_in_segment.begin, IO::SEEK_SET)
bytes_to_serve_for_segment = range_in_segment.end - range_in_segment.begin
IO.copy_stream(segment, client_socket, n_bytes_to_serve)
end
In summary
Yes, true random access to dynamic HTTP resources is difficult to achieve. Streaming is easier, but you will need to be careful with memory bloat if you are using a garbage-collected language. But the few times you do need’em - you can make’em happen, as long as you “do the right thing” throughout the pipeline. Most likely you can make your life much easier if you skip certain constraints of this process - for example, remove the requirement of resumable downloads or the requirement that responses be pre-sized.
What is a reduction and why fibers are the answer for Ruby concurrency
In the Ruby 3 features, a lot of attention went to Ractors - a new parallelism primitive which provides what can best be described as “Web Workers” - separate threads of execution with memory isolation from the spawning thread. However, there was also a release of a seemingly “nerdy” feature which is the FiberScheduler.
Ractors still have to prove their own (my dear friend Kir Shatrov has done some exploration into designing a Ractor-based web server) but I would like to highlight that second feature, and the concept of scheduling and reduction in general.
I strongly believe making good use of Fibers is instrumental to Ruby staying relevant for creating web applications. As a community we are in a tight squeeze now, between Go on one side and Node.js on the other side, and the concurrency story in Ruby isn’t that good compared to either of the two - however we stand a measurable, substantial chance of once more getting ahead of the game. Especially considering that Python3 has chosen for the “colored” functions model with its asyncio setup. See Kir’s article for an interesting perspective on this too.
See, when people talk about Ruby parallelism and concurrency usually the conversation is quickly curtailed by the first person who screams “But the GIL! So there is no parallelism!” and then the room falls silent. In practice the situation is much more nuanced, and gaining a better understanding of the nuances will make your Ruby programs faster, more efficient and let you use less compute. If you know where to look.
A whirlwind tour of Ruby concurrency (and parallelism)
The current situation in Ruby using threads (the native Thread primitive) is basically as follows. Imagine we have multiple threads (listed vertically) which are performing some work concurrently, and the time is on the horizontal axis:

The red sections are executing MRI opcodes - some kind of Ruby code work. This can be Puma threads, or Sidekiq threads - anything you can meaningfully parallelize. However, there is a GVL (Global VM lock) which ensures that no two Ruby opcodes can execute in parallel. The reasons for that are curious, but mostly they have to do with a very thin layer between raw C pointers - which native code uses inside MRI, for things like memory allocations, IO and calls to libraries such as Oniguruma. Since Ruby threads are pthreads - POSIX threads - if this lock gets removed multiple threads can perform the native calls at the same time. This can call out into not-thread-safe APIs also, and more of them exist than you could think of. For instance, ENV[...] - the getenv() call - is not thread safe, and without having a mutex you would have to contend with that in your Ruby code. So, in practice, when all your threads are executing Ruby code, what you get is so-called between the lines concurrency - similar to what you have in Node and in the browser Javascript engines:

When a thread is executing Ruby code other threads cannot obtain the GVL and have to wait. Now, if you are at a roundtable of grumpy developers who can’t wait to switch your entire team to Java or Go this is where the conversation usually ends. “There is no real concurrency, so there is nothing to discuss in here” lauds the answer, and plans get drawn to rewrite perfectly workable software for a different runtime. However we need to dig a little deeper - not only to have a healthier, more informed conversation about the topic, but also to understand how your program gets executed.
Testing concurrent code with Ruby fibers
A second time I stumble upon a situation where I have a method which takes a block, and runs that block in a certain context. This is the Ruby pattern we are all familiar “with” (pun intended):
with_database_connection do |conn|
conn.batch_insert(records)
end
The most familiar usage of this pattern is, of course, with File objects - we enter a block with the opened file, and the open method then ensures that the file gets closed when we exit the block.
What I found to be tricky, though, is testing that this block creates a certain state and holds that state during the duration of the block. For example: at $company a number of our services use locks of some kind. Implementing locking can be done with “lock objects” or “lock tokens”, in which case your code would likely have a shape like this:
def do_massive_work(on_some_object)
lock = acquire_lock(name: "some_object_#{on_some_object.to_param}")
do_some_work
ensure
lock.release
end
This works fine, and a lock like this is pretty easy to test. For example, with RSpec:
lock = acquire_lock(name: "lock1")
expect {
acquire_lock(name: "lock1")
}.to raise_error(Locked)
lock.release
expect {
acquire_lock(name: "lock1")
}.not_to raise_error(Locked)
But this kind of API is a bit… wordy. With these lovely with_... blocks used all over the place it shouldn’t really be necessary - introducing this API beneath the with_.. one feels like doubling your interface surface just for the sake of being able to test your interface.
The particular case I needed this was when I wanted to partake in the (quite neat) feature of MySQL called GET_LOCK() which gives you a user-level named lock token. It is pretty dandy, as you can do this:
SELECT GET_LOCK("object_graph_from_user_123", 2); -- Second argument is how long you are prepared to wait for the lock to become available
UPDATE comments WHERE author_id = 123 SET ...;
UPDATE uploaded_pictures WHERE uploader_id = 123 SET ...;
SELECT RELEASE_LOCK("object_graph_from_user_123");
If you have a task which manipulates an object graph, and you want to have only “one” of that task to run at the same time (networks are hard, and nothing in the world is perfect, but it does mostly work) the GET_LOCK() function is a pretty neat feature. ActiveRecord even uses this functionality to ensure that you cannot run multiple migrations at the same time, but those functions are not exposed as part of the public API. Imagine we want a module which provides a with method which would work like this:
DBLock.with("lock_1") do
#... do something while holding the lock
end
Writing the module is not hard at all:
def self.with(lock_name, timeout_seconds: 5)
qname = ActiveRecord::Base.connection.quote(lock_name) # Note there is a limit of 64 bytes on the lock name
did_acquire = ActiveRecord::Base.connection.select_value("SELECT GET_LOCK(%s, %d)" % [qname, timeout_seconds.to_i])
raise Unavailable, "Unable to acquire lock #{lock_name.inspect} after #{timeout_seconds}, MySQL returned #{did_acquire}" unless did_acquire == 1
yield
ensure
ActiveRecord::Base.connection.select_value("SELECT RELEASE_LOCK(%s)" % qname) if did_acquire == 1
end
And now the fun part: how do we test it? How do we verify that a lock can only be held by one thread or process?
Way back in 2008 I suggested using artisanal sleep() calls to make concurrent calls happen, but it has several problems:
- It is slow. Your test will be sitting there waiting in the
sleep()and you will be sitting there waiting for your test to pass. Not ideal. - It only checks mutations - the outcomes of an operation, not a continuous interval of time when a certain state invariant is in force. Not ideal.
- It is not deterministic - it is hard to predict which of the threads will win.
Luckily, in our modern Ruby world, there is a much better alternative and that is using Fibers. I’ve covered some Fiber properties in an article I wrote for Appsignal and you could read up there if you want to refresh your memory about how Fiber works. What’s important for us in this case is that Fiber contains within itself a pause button - the Fiber.yield method. Yielding from a fiber means that you literally tell your code to “drop dead” and suspend itself, until you imperatively resume the code with Fiber#resume - this one is an instance method on the Fiber itself. In essence, what people want to say when they posit that “Fibers are for concurrency” could better be worded differently: “Fibers are for sequencing” - they allow you fine control over in which order code is going to execute.
Now, one might wonder: this is a strange contraption and how exactly is that useful for testing our lock?
Here is how it is useful. We will suspend our code while the lock is held. We will enter the section and obtain the lock in one Fiber which we will then suspend. When that Fiber yields to us we know that it is holding the lock within itself, and it won’t release the lock it is holding until we #resume it again. Fibers are “callback-like” and when dealing with this kind of code - for me - it is really really hard to visualise mentally what is going on. What I found helps a ton is just putting the “execution line numbers” next to your code when trying to understand the flow. So:
fiber = Fiber.new do
acquire_lock
Fiber.yield
release_lock
end
fiber.resume
fiber.resume
will be executing roughly in this order:
fiber = Fiber.new do
2) acquire_lock
3) Fiber.yield
5) release_lock
end
1) fiber.resume
4) fiber.resume
When we do the first #resume we are entering the fiber, and acquiring the lock. Then the Fiber will yield back to us and suspend itself. Then we #resume it again and the Fiber will execute the remaining code within itself, to completion. What applies to method bodies also applies to locks, and crucially - our almighty pause button which is the Fiber.yield call - is going to execute in the block as well. So we can place our block into the Fiber:
fiber = Fiber.new do
DBLock.with("lock_1") do # This is the same as our line 2)
Fiber.yield # Pause at line 3) with the lock still held by us
# Running the block to completion means that the
# `ensure` of `with` will be called and it releases the lock
end
end
fiber.resume # Bam! Now the lock is held within the suspended Fiber
expect {
DBLock.with_lock("lock_1") do
raise "Should never be reached"
end
}.to raise_error(DBLock::Unavailable)
That gets us rid of all of the issues of our previous solution with sleep():
- It is deterministic - our second call to try to obtain the lock is guaranteed to happen after the Fiber we created already grabbed the lock and is before it has released it.
- We are testing the existing continual state of the system - the lock is held when we do our assertion. We don’t need to check “saved outputs” of something.
- We don’t need to wait for any sleeps to complete and we can proceed to assert directly
In this instance we need to ask for a 0-second timeout for things to be near-instant, but the gist still holds.
With the particular module I am describing there was a catch of course (isn’t there always): by default this is not going to work 😢
For some reason our test.. still fails. And there is a reason for it. The reason is that these locks in MySQL are reentrant within a connection, meaning you can obtain them multiple times:
SELECT GET_LOCK("lock_1", 1); -- returns 1
SELECT GET_LOCK("lock_1", 1); -- returns 1 too!
SELECT RELEASE_LOCK("lock_1"); -- will return 1
SELECT RELEASE_LOCK("lock_1"); -- will return 1
SELECT RELEASE_LOCK("lock_1"); -- will return NULL
This is useful - it means that within a single SQL session you won’t deadlock with yourself. It also means that you have to RELEASE_LOCK as many times as you have done GET_LOCK since this locking system has a checkout counter, but that being said: for our testing this is a negative, because by default ActiveRecord::Base.connection will give you the connection currently checked out for use by the current active thread. Meaning - both your assertion and your Fiber will be using the same connection, meaning that they will be able to grab two instances of the lock. You will only be refused on the lock if you try to obtain it from a different MySQL connection, which - in ActiveRecord terms - must be another connection object. And there is a place to get that from - it is the connection pool:
ActiveRecord::Base.connection_pool.with do
DBLock.with_lock("lock_1") do
# ... do our locky stuff
end
end
Except… that won’t work either, because within our Fiber we still are inside of the same Thread, and the ActiveRecord::Base.connection is still the same object! So even if we change our test to do this:
fiber1 = Fiber.new do
ActiveRecord::Base.connection_pool.with do
DBLock.with("lock_1") do
Fiber.yield
end
end
end
fiber2 = Fiber.new do
ActiveRecord::Base.connection_pool.with do
DBLock.with("lock_1") do
Fiber.yield
end
end
end
fiber1.resume
expect {
fiber2.resume
}.to raise_error(DBLock::Unavailable)
our test will still fail, since we are checking out a connection from the ActiveRecord pool but not acquiring our locks through it. And thus, begrudgingly, we change our with_lock to this:
def self.with(lock_name, timeout_seconds: 1, for_connection: ActiveRecord::Base.connection)
qname = for_connection.quote(lock_name) # Note there is a limit of 64 bytes on the lock name
did_acquire = for_connection.select_value("SELECT GET_LOCK(%s, %d)" % [qname, timeout_seconds.to_i])
raise Unavailable, "Unable to acquire lock #{lock_name.inspect} after #{timeout_seconds}, MySQL returned #{did_acquire}" unless did_acquire == 1
yield
ensure
for_connection.select_value("SELECT RELEASE_LOCK(%s)" % qname) if did_acquire == 1
end
We are going to pass the connection to the method and have it acquire the lock through that particular connection:
fiber1 = Fiber.new do
ActiveRecord::Base.connection_pool.with do |conn|
DBLock.with("lock_1", for_connection: conn) do
Fiber.yield
end
end
end
fiber2 = Fiber.new do
ActiveRecord::Base.connection_pool.with do |conn|
DBLock.with("lock_1", for_connection: conn) do
Fiber.yield
end
end
end
fiber1.resume # Bam! Now the lock is held within the suspended Fiber
expect {
fiber2.resume
}.to raise_error(DBLock::Unavailable)
and indeed, the test now passes!
Same trick can really be applied if you want to “suspend” inside of a different method. Imagine you want to have this locking facility within an object, and you place it in a Module that you prepend. Say, with a background job that you reeeally want to run only one of at the same time:
module OnlyOnce
def perform(*args)
with_lock("job_abc") do
super
end
end
end
and you want to test that module. What do we do? Well, we can apply the same trick - except that we will need an object which does Fiber.yield from its perform. You can yield this way from anywhere, not only from a hand-written Fiber.new do... block.
job_mock_class = Class.new do
prepend OnlyOnce
def perform(*)
Fiber.yield
end
end
fiber1 = Fiber.new do
job_mock_class.new.perform # Our module takes the lock and calls super, and super suspends inside of itself
end
fiber1.resume # now we are holding the lock
This applies to any situation where you might want to test code which enters some block and must stay within that block while you make test assertions. Just think of the magic ⏯ and the rest will unwind by itself.
Stealing the better parts of Go libraries into Ruby: interval_response
The Go programming language is a curious piece of a kit. Unquestionably successful, no doubt about it - and lots of high-profile Rubyists have taken a liking to it or even moved wholesale (and then espoused vibes to the tune of “I am not using a testing library, look why I am morally superior” and “I run 2 servers instead of your 10, look how much better I am”). Personally, I am not fancying Go that much - primarily because of disagreements with some of the Go authors’ attitudes. I understand their motivation for many design decisions, but take the freedom to disagree and abstain instead of “disagree and commit” as long as getting something done doesn’t require me to work Go specifically. And mind you - there are tasks where Go is undisputably excellent and no better alternative exists. Like making commandline binaries for cross-platform distribution, for instance.
But as much as I have complaints about the built-in language constructs, the condescending existing-but-not-end-user available generics, a (myriad of) byzantine dependency management system(s) and whatnot – let me be very clear on something. The standard library in Go – and many third-party libraries are, by any means, near-stellar. It has a lot of very specific, very useful primitives which, in large, are informed by production concerns which have been encountered by the authors. Timeouts and cancellations, contexts, multi-step HTTP connection setup which allows fine grained control over socket use - brilliant. Even when the anemic language constructs make these libraries screech and wail the library doesn’t become less great - and from a Ruby perspective we are spoiled by having a pretty rich standard library to begin with.
One of the great things (maimed by backwards compatibility, and yet) in Go is the ZIP library - archive/zip which served as one of the inspirations for zip_tricks in terms of functionality and the API. It certainly did find some use during the making of the Google download servers, as described in bradfitz’ presentation and the approach was very influential for us when making ours.
Another bit of excellent standard library mojo which comes from this download server experience at Google is the oddly named serveContent function from the net/http package - which hides a few great devices under the hood, the disguises of its modest signature. The function is quite neat in that it implements random access to an arbitrary resource (anything that implements io.ReadSeeker) and allows this random access to be excercised by the client using the Range: HTTP header. The function even is able to serve multipart responses - something S3 doesn’t even support. So quite some sophistication down there. Although it has its own share of problems, which follows Julik’s Law Of Private Final Sealed Concrete API separation principle:
If the author of a library is forced to mark things as inaccessible to change or overrides, exactly the parts which need changing or overriding the most will get marked inaccessible - see also)
Now, Brad’s presentation includes another interesting bit of information. which is that you can assemble a virtual IO object (what this io.ReadSeeker actually is - it is an amalgamation of the Read() and Seek() methods) which represents multiple files (or objects on a remote storage system - such as S3) by stringing those objects into a single, linear IO. Kind of like so (for our ZIP situation):

This allows us to create a “virtual” HTTP resource with random access even though this resource is, under the hood, stitched together from multiple parts which are never stored together in one place. Brad achieves it using an object called a MultiReaderAt or a MultiReadSeeker. This is the part where I cheat - even though it was proposed to add it to the Go stdlib one has to look at the implementation made available as part of Perkeep. But it still can be found in the linked docs.
This multi-reader-seeker-closer-atter (this Go interfact composition thing is beautiful when there are no generics, right?) internally uses one of my favourite algorithms - binary search. It gets used to quickly find the right segment. Imagine you have the following list of segments that you want to “splice” together:
ZIP header (64 bytes)
S3 object (1297 bytes)
ZIP header (58 bytes)
S3 object (48569 bytes)
ZIP central directory (886 bytes)
Imagine we get a request for the following Range: - bytes 1205-13605. We would need to first read bytes 1141-1296 from our second segment, then bytes 0-57 from our third segment, and finally bytes 0-12186 from our fourth segment to fulfill that request. This is where the binary search comes in! Imagine we store our segments as tuples of {size, offset}. Then we would have a list of tuples of this shape:
{size=64, offset=0}
{size=1297, offset=64}
{size=58, offset=1361}
{size=48569, offset=1419}
{size=886, offset=49988}
We could scan the list from the beginning, looking for the offset value which is at or below our requested range start, and then do another scan (or continue our initial scan) until we find the tuple which covers the end of our range. Then we do a bit of arithmetic to get the range “within” the segment, by doing requestedRangeStart - segment.offset and requestedRangeEnd - segment.offset and let the segment “read” itself. Or read it externally. For example, dropping back to Ruby
segment.seek(range_in_segment_start, IO::SEEK_SET)
segment.read(range_in_segment_end - range_in_segment_start + 1)
But if we have a very, very long list of ranges? Imagine a ZIP file with 65 thousand files, that makes it a segmented response composed of no less than 130001 segments, if you remember your ZIP file format structure. If we only need to return one range, then we’ll have to do 1 scan, worst case passing 130000 entries. This can get pretty expensive pretty quickly, and will need even more optimization if multiple ranges are requested (and we do want to support that use case). This gives us linear - O(n) performance, where n is the number of segments.
This is where binary search comes in (and of course, it is used in the MultiReadSeeker too, by applying the sort.Search function): since the segments are sorted by their offset we can reduce the complexity to O(log n) by splitting the search list in half each time we drill down. The best illustration of the binary search algorithm from Wikipedia:

Ruby Arrays have a built-in method called #bsearch, which, by default, uses the same semantics as the “boat operator” (<=>) - normally used for sorting. The standard setup of bsearch implies that you can return the result of <=> from the block and this is sufficient for an exact match (0 means “found”).
Since we are looking for an inexact match we will have to alter the search block like so:
@intervals.bsearch do |interval|
# bsearch expects a 0 return value for "exact match".
# -1 tells it "look to my left" and 1 "look to my right",
# which is the output of the <=> operator. If we only needed
# to find the exact offset in a sorted list just <=> would be
# fine, but since we are looking for offsets within intervals
# we will expand the "match" case with "falls within interval".
if offset >= interval.offset && offset < (interval.offset + interval.size)
0
else
offset <=> interval.offset
end
end
Note that a peculiar property of the boat operator is that it is not commutative because it is a message on the receiver rather than a function (in this instance, the <=> implementation on offset, that is - on an Interger - decides the outcome of the comparison).
This allows us to use our “intervals IO” for various purposes - for example, feeding a segmented file to our own format_parser and have it be accessed as a single entity. The code below covers the entire subset of IO that FormatParser requires:
class RopeIO
def initialize(*ios)
@seq = Segments.new(*ios)
@pos = 0
end
def seek(absolute_offset)
@pos = absolute_offset
end
def size
@seq.size
end
def read(n_bytes)
buf = String.new(capacity: n_bytes)
read_range = @pos..(@pos + n_bytes - 1)
@seq.each_in_range(read_range) do |io, range_in_block|
io.seek(range_in_block.begin, IO::SEEK_SET)
buf << io.read(range_in_block.end - range_in_block.begin + 1)
end
@pos += buf.bytesize
buf.bytesize == 0 ? nil : buf
end
end
By the way, a different surprising use of this pattern is constructing a non-linear editor timeline, for both video and audio. Observe:
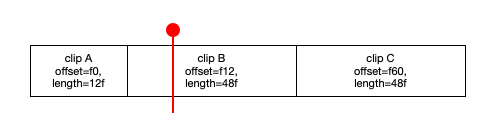
If you are thinking DAW then replace the frame numbers/counts with sample numbers/counts. In this situation, the most efficient way of finding the frame under the playhead will be using the same approach (use binary search to find the segment underneath the playhead, then add the local offset of the playhead within the clip to the “edit in” point of that clip, in this case it is Clip B).
Once we have our “splicing IO” bit covered, we can expand our abstraction “upwards”. Where Go has its http.ResponseWriter object we have our Rack specification and its iterable bodies, and we have the Rack utility methods (the aptly named Rack::Utils module) for parsing our Range: headers. This is where the Go implementation of serveContent() shows how privatizing parts of the API willy nilly creates a bad user experience: there is no way to take and use just the parser of the Range: header. In Rack it is readily available plus there was less incentive to privatise it, meaning that it is a stable API we can rely on. As long as we follow Rack’s semantic versioning guarantees at least. So:
range_serving_app = ->(env) {
ranges_in_io = Rack::Utils.get_byte_ranges(env['HTTP_RANGE'], interval_sequence.size)
...
}
Of course, we also need to furnish some kind of a readable body - an object that responds to each and yields Strings into the passed block. My former colleague Wander recently wrote a neat article about streaming in Rack and you might want to have a look at it for a refresher. Since we have our segment_sequence object available, and this object supports range queries, we can construct an object which will “dig” into our IOs and return the data from the requisite ranges:
class RangeResponseBody < Struct.new(:segment_sequence, :http_range)
def each
segment_sequence.each_in_range(http_range) do |io_for_segment, range_in_io|
# To save memory we will read from the segment in chunks
bytes_to_read = range_in_io.end - range_in_io.begin + 1
chunk_size = 65 * 1024
whole_chunks, remainder = bytes_to_read.divmod(chunk_size)
io_for_segment.seek(range_in_io.begin, IO::SEEK_SET)
whole_chunks.times do
yield(io_for_segment.read(chunk_size))
end
yield(io_for_segment.read(remainder)) if remainder > 0
end
end
end
and we then wire it into our Rack application, roughly like so:
range_serving_app = ->(env) {
interval_sequence = ...
ranges_in_io = Rack::Utils.get_byte_ranges(env['HTTP_RANGE'], interval_sequence.size)
iterable_body = RangeResponseBody.new(interval_sequence, ranges_in_io.first)
[206, {}, iterable_body]
}
Of course there is also some bookkeeping to do so that we return the correct Content-Range header, so that the ETag reflects the composition of the segments and the like. And, before long, we have carried over most of the serveContent + MultiReadSeeker goodness from Go. And it now lives happily inside our download server. Needless to say, you can also use it - find it on Github
So - serveContent is a really neat invention, and porting it was a great and fun excercise. For one - it reaffirmed my belief in the value of open polymorphism. There is no casting anywhere - anything you want to compose into an IntervalSequence will be given back to you once you start iterating over objects, and it is possible to actually use something else than IOs entirely, making it more useful - see above for the video clips on a timeline example.
Also, it presented a great use case for “sum types”. Although Ruby is no Haskell, nothing cancels the fact that we can return an object which conforms to a certain interface, and that interface is one and the same - yet we can return different values for each type of response that we want. In interval_response we have 5, with Multi, Single, Full, Empty and Invalid being the variants, which all get used the same. Of these, Multi is probably the most involved. As Sandy Metz suggests, we do inheritance here - but not for the sake of typechecking, but so that there is a piece of code that outputs a sensible piece of documentation with regards to the “baseline” methods such an interval response must support. And the inheritance hierarchy is “wide and shallow”.
And finally, it gave me the opportunity to “cut” between the private and public API sections much more rigorously and with less disadvantages for a user, as smaller blocks compose better and are also much more pleasant to test.
Splendid. Great ideas port well.
Super fast signing of s3 URLs
This post was written by Luca Suriano and myself. Luca deserves most of the credit and has done the bulk of the work on the software mentioned. Special thanks to Jonathan Rochkind who stimulated us to finally share this post by publishing his own research into the matter.
We all know how boring it is to sign a big pile of documents. Tax returns anyone? At WeTransfer we need to create signed URLs to files, but fortunately for us, we’re not in the old days of Johannes Gutenberg anymore, as we do it automatically.
New inventions brings new problems, and we soon discovered that for transfers containing more than a couple of thousands of files, the process was really slow, causing annoying timeouts to our users.
The answer lies on the wise words of someone, whose respect, goes far imaginable for pushing the boundaries: Make It Work Make It Right Make It Fast, Kent Beck
What can we change in order to reduce the time required to sign these big transfers? Can we do better? Can we go faster?
The answer is: yes, we can go 45 times as fast!
Workstations are underrated
We live in interesting times, and it has finally dawned: many software engineers and designers who wanted to work from home are finally able to. And this brings us to the subject how we work as well.
A number of years ago it has become fashionable to work off of laptops. It had a large number of advantages, but in the first place it meant the escape from “the beige”. It meant that you no longer had to be at the office to get your job done - and that your hardware could be your own property, and you could carry it anywhere with you. Feeling like the office is bringing you down? WiFi is ubiquitous, so pop by your neighbourhood hipster-friendly coffee place and work from there. Want to quickly check the email? No problem - grab the machine out of your messenger bag, pop it open, do the work. Need to do an instant intervention on your company server? Sure thing, roaming access and SSH got you covered.
In fact, laptops have changed the “computer work” culture to a larger extent than the removal of cubicles did. The open office these days is hard to imagine without rows of laptops perched up on laptop stands.
But not all is rosy. Although being able to “work from anywhere” is very appealing – and logistically amazing sometimes – there are things which you are getting “in the package” with the laptop culture which, come to think of it, are not at all so rosy.
Work happens anywhere, which is not always great
It is a luxury these days to have a private cubicle or – thu luxury of luxuries – a private office. Something as ubiquitous as a shed (schuur), a staple of a Dutch dwelling, has become impossible to obtain - at least in Amsterdam. But the benefit of having such a spot is very underrated, yet immesureably substantial. It is that work has a place. You don’t go logging into that server at dinner. You don’t zone out into your work email when sitting on the couch with your partner. If the computer is stationary - and you have to actually walk to it then “working at the computer” becomes a conscious, deliberate action. Laptops condition you to the fact that work can be done anywhere, and they actually also motivate you to use this advantage more often. As the end result, work bleeds into more areas of your life where actually quiet contemplation would do much better. If work can be done anywhere - have no doubt, modern capitalism and incentives will make sure that it will.
Now, ther are a few amazing patterns where laptops enable, by way of their limitations. For example, you want to write something and you go to a coffee bar next door to “zone out” and finish your piece. Since your laptop has a limited battery you effectively impose a “sprint” of sorts upon yourself, since you know that the time you can spend at that spot is limited. But this pattern - at least for me - has proven of limited utility.
When COVID-19 started I’ve noticed that having a fixed spot for “doing work” at home was a way better idea than dragging work with me all around the place.
Performance and thermals, which suck
Laptops are devices built with inherent engineering constraints. They usually have limited active cooling, and thus they need to have limited performance characteristics, as modern circuits are packaged very tightly and generate an incredible amount of heat. This heat, if left unchecked, can make equipment fail, or even cause fires - so a laptop is naturally limited in the amount of performance it can put out. Funnily enough, when a laptop does have active cooling - like the Macbook Pro dual fan setup - this setup can be noisier and more obnoxious than the bigger fans that can be used in a desktop machine, as the noise they generate is produced closer to the person using the machine, right underneath the keyboard. Moving parts also have to spin at a higher speed, because the cross-section of the fan is limited due to the device footprint. Some laptops also transmit quite a bit of vibration from the fans into the body and the enclosure as well. And the modern Electron technology is always available to consume that compute.
Performance is also subpar as laptops are unable to house a high-speed GPU or a very power-hungry processor. For instance Ryzen laptops have only recently started coming to market, not in the last because of the large size (and power consumption) of the chip.
Noise, which is right where you don’t want it
It might seem strange - but under heavy load a laptop with all the fans spinning at maximum speed is more obnoxious to listen to than a workstation. Also, a laptop is always right next to you. Workstations can be located away from where you work, in a spot where adequate sound isolation is provided, and you can - in fact - isolate yourself completely from any noise your computer might be producing. Back in the day when I was working in a Flame suite the screen and the input devices were normally located in a different room than the operator even - the computers would then have their own spot on a rack with ample cooling, and a long run of wire would connect to the screen - which allows one to work in complete silence.
Docks and dongles, which do not work all that well
Laptops are inconvenient to connect to peripherals. Back in the day it was passable - there was a power cord (I still do not own any machines without MagSafe and do not feel like owning one will add any happiness to my life and well-being), the requisite USB ports and maybe a DisplayPort connector. Worked well enough but now we are in this brave new world of USB-C. Screens that do not work. Power that doesn’t get transferred and devices that do not charge. Ports on the left that are exactly the same as on the right but yet they aren’t. Adapters necessary for everything and cables which all have the same connectors yet do not support the 2 functions of the 3 you invariably need to be supported.
Frankly, it is horrible. Most of the people I know working with laptops also do have a “fixed spot” at the office - where the whole shebang of peripherals invariably needs to be connected to the machine, and then unplugged at the end of the day. And even with pre-USB-C Macbook Air 11” (which I consider one of the best machines Apple has ever put out there) one out of 10 times the external screen will fail to reconnect correctly. And sometimes the devices do not get reconnected correctly either. A workstation is always plugged into the right peripherals, with actual stable cabling.
Sadly enough, no modern contender to a Powerbook Duo has emerged to date, which is a shame. Yes, there are dock-like USB-C hubs but even the best of them turn out to be somewhat unreliable.
Network, which is just plain better with wires
I remember when WiFi was something new and amazing - it was a great novelty and an enabler. Yet, even then, compared to just a modest 100Mbit Ethernet connection, it sucked. Even though WiFi speeds have gotten better, equipment has gotten more robust, and the whole thing has become more affordable WiFi still cannot reliably produce 1GBit of throughput. Meanwhile, a network card with some Cat6 wiring can already, today, give you 10Gbit of throughput - without dropouts and signal degradation. And don’t mention congestion. On my street, every apartment is running a network. And every bar in the street (of which there is a dozen within radio range) is running one too - on more powerful hardware as well. All of this really doesn’t make the networks more reliable or speedy - on the contrary, the more networks share WiFi channels the slower things get, for everyone. A workstation doesn’t even need to be on WiFi as you can just leave it plugged into an Ethernet cable, day in and day out.
See Wireless is a trap for more in-depth information on this.
Posture and health, which suffer a bit
Strangely enough, using a laptop turned out to be a net negative for me in terms of health. The problem turned out to be the neck strain. See, when a laptop is on your, well, lap - or on a desk - you have to look downwards to see the screen. For me this has created some cramps in the neck muscles, which then started manifesting as pretty severe headaches. As it turns out, the effects were gone the moment I stopped using laptops for longer than 10-15 minutes and started using a stationary, big display positioned at the right height. Which is not all that hard - a decent screen can be had for just a few hundred countable money units these days. And most people at offices use laptops tethered to external screens anyway.
So….
Well I did actually have a workstation all that time, it just wasn’t getting that much use. The laptops I have been buying were always the “bigger” 17” Macbook Pro’s (remember those?) and they were meant to be plugged in at the home office as well as at work. But I also needed all that screen real estate at work, because – believe it or not – for the better part of the near 8 years of my tenure at Hectic I didn’t have a desk. There were just two Flame displays in the two “suites” and whichever square centimeters I could use next to them to place my laptop. And since Flame was running Linux, using some direly necessary software - even Photoshop - was difficult.
But I always wanted a decent box at home. So when my Mac Book Pro gave up the gost due to a well known tragic situation involving Apple showing nVidia the finger and then showing its customers the finger I bought a trashcan mac, and honestly - didn’t use it much. First it fell victim to - you won’t believe it - another GPU failure. But that one could be rectified and fixed, and once COVID started I moved most of my work to that machine. And man o man does it make a difference, even though it is 7 years old.
If you can - indulge yourself and get a workstation, you might be surprised how well the ancient computer clerks - of the decades gone - by had it.
Why your should keep project management out of your commit titles
It is pretty usual to prefix the commit titles in your repository with the ticket number of what this issue resolves. Something like this:

I would like to make a compelling case for why this is not a very good idea to begin with, with one small exception.
As we know, Git commit messages have pretty strict guidelines on how they should be formatted. The guidelines are well known, and just to recap: a Git commit message consists of a commit title - hard-limited in display to 50 characters - and of the commit message body.
Even though the commit title size is arbitrarily chosen - for reasons such as using it in an email subject line when generating a patch - the fact that we are using Git and are about to be using Git for the foreseeable future means that this is a hard limit. And it does have consequences. Long commit titles are not pleasant to deal with. They have rather ugly overflow in Github:
and they get very long in Git commandline display:
$ git log --pretty=oneline
a4b4f44 (HEAD -> git-commit-titles, origin/git-commit-titles) DJYRA-745 feat/task: Modify shlobulator to explicate the conflagrator. We need to derezz the flux core for this.
0eef372 (origin/master, origin/HEAD, master) Fix image scaling on mobile
5233646 Customise the feed URL
And here is the rub: 50 characters is very little. It is less than the 140 characters you get on Twitter for example. And most tools you are going to be using are going to be truncating to this length by default. For example, GitX:

Of those 50 characters, the standard pattern of 4JRA-1234 consumes 9 characters (if you count the space after it). Almost a fifth of the useful information you can provide to the reader. And where the reader is involved, we get to the purpose of those commit messages.
They are meant to communicate something to the person who is going to be looking for a possible defect or a change that you have introduced. Possibly years after your work is complete. When you cram your JIRA ticket numbers in there, you waste the space in the commit title which is at a high premium - to imprint your project management methodology du jour into the project. And it gets way less neat because of this simple maxim:
Trends in project managment tools change. Code stays.
A codebase can outlive a number of different project management tools throughout its lifetime. I am working on a codebase that has survived, in no particular order:
- Assembla
- Trello
- Gitlab
- Github
- JIRA (multiple projects thuis prefixes)
Once a codebase (and a software project, or a software team) switches tools, in every single one of those cases the “previous” project management tool ended up being discarded and projects closed. It is no longer possible to find A485, and no longer possible to find T523 either, even though they stand front and center at the start of every single commit. When dealing with defects or incidents it actually becomes a problem - because exactly when the information about the what of a particular change is the moste direly needed - what the reader finds instead is a runic image of a project management tool this person has never seen. And can no longer consult.
Moreover - three of these were “off-repo” numbers. By “off-repo” I mean that they were numbers assigned to things which were not integrated with the source management solution in use at the time. To extract any and all possible use from these, you would need to install a browser extension or an SCM plugin which would make these numbers clickable, so congratulations - you also just added another step to your onboarding procedure if you want to cover that.
And once these numbers really go up (may your software project have a long and prosperous history!) these numbers start eating into your commit titles - big time.
Github and Gitlab form a good exception to this rule - they hyperlink the pull/merge request at the end of the merge commit title because within the system hosting the code this reference (the #123) is clickable by default. And since it is clickable by default this is the only issue/ticket reference you should tolerate in your commit titles – everyone onboarded onto your code hosting system fo choice already knows how to use it.
Semantic commits are also not that great
Semantic commits also want to bite away a piece of your 50 characters, with prefixes like:
chore: Update libswap to 0.4.2
feat: Modernize the user card view
The reason why semantic commits have the same issue as the issues is that they capture transient intent - or, to be more sharp - your opinion on project management strategy that is anchored in time within a resource that is much more persistent than the said opinion. What you consider a Task today might as well become a Feature tomorrow when the backlog grooming reprioritizes your user story. What today is a chore might actually be a feature significant upgrade of an important component you are using all over the place.
Aside -
choreas a word strikes me as odd because one could just as well putshitwork: Apply critical security update to libwebserver 4.0to the same effect. Taking care of your code is not a chore, it is something that we should be doing with respect and dignity. You usually need that libwebserver up-to-date.
In other words: semantic commits imprint a limited, managerial perspective on software project management into commit titles, and there is a chance this limited view is not going to age well or reflect the actual impact of the change.
There is arguing that those chore: prefixes can disclose why a certain change was applied, but hear me out on this one. Imagine a hypothetical SRE diagnosing an issue in your application. They see a list of commits like this:
chore: Update libdarkwater to 0.4.1
chore: Update libdarkwater to 0.4.0
feat: Ensure resolution interpolation is off for images smaller than 1024px
These so-called “semantic prefixes” tell you very little - they tell you what the person committing the changes though their changes were from the perspective of the project management and impact. To demonstrate, let’s see what happens if we remove the “meat” of the commit titles and only leave those labels:
chore:
chore:
feat:
This does not fullfill the most important purpose of code and its metadata - it does not communicate intent, the “why” of the change. The most the SRE will be able to deduce from them is “so the developer proooobably thought that this was just a dependency update?…” but this is not guaranteed at all.
Here is what is important instead: “Which of these commits introduced an issue?” The semantic commits do not communicate this one bit. They also do not stand their ground in the case of feature domino failures (if the resolution interpolation specifically in combination with libdarkwater 0.4.0 causes all the images to become pink, for example).
If we remove the semantic commit prefixes:
Update libdarkwater to 0.4.1
Update libdarkwater to 0.4.0
Ensure resolution interpolation is off for images smaller than 1024px
the useful information still ends up being retained. Tip: - if you se a modern dependency update service such as dependabot or Depfu you will be able to see the icon of the service in Github, which will conveniently replace the commit title bits.
What you really want instead
Both issue numbers in titles and the attempts at “classifying creative work” in semantic commits actually try to do very similar things. They try to point (issue numbers) or try to explain inline (semantic commits) the reason why a change was applied. And there is a great tool for that which already exists - it is writing good prose. The commit body has all the requisite space for you to
- Tell the reader why that change was applied
- How it felt to you it was applicable. Was it really a chore? or was it direly necessary since your application was to be little-Bobby-tabled?
- Who requested and authorized the change - sometimes very important, because lots of things transpire due to politics and exposing those politics can be very helpful when troubleshooting later
- What issues were encountered
Do your reader a favor - write prose instead, and take time to explain as much of the why as you possibly can. With all the issue numbers - and even better - URLs - without having your reader investigate “what was this weirdo XYZ issue tracker they were using back then?”
Your minimum viable Rails service pattern
Service objects seem to be coming into fashion every year or so. I would love to share an approach that I use for service objects (which are actually service modules). It works very nicely, promised!
Update: this article calls for the same approach more or less
Oh, Sprockets
There’s been this whole conversation on Sprockets lately. I must admit I tried hard to stay away from the discussion for the most part, but I thought that maybe providing a slightly different perspective might be interesting (or at least entertaining) for some.
The reason for writing this piece is, among others, because I feel let down. I must admit that right now I find myself in a state that can best be described as JavaScript paralysis. This is what comes after JavaScript fatigue. I hope to recover soon, since my ability to deliver is severely impaired because of it. Maybe Gile’s book will help. I hope it will otherwise I might go into therapy. And I feel that the Sprockets situation is at least partially to blame for this, if not directly then by collateral - so just let me vent for a little, mmkay?
For those who didn’t follow - Giles says that Sprockets is not worth saving, and advocates integrating with the wider JS ecosystem and trying alternative approaches instead. Schneems took on the gargantuan task of dragging Sprockets, kicking and screaming, into the brave new world of the blossoming JS we all love so much. Please read both the articles before reading this on.
DISCLAIMER: this is a 100% opinion piece.
Bad API design: a whirlwind tour of strong_parameters
Lately I have been doing time upgrading an application from Rails 3 to Rails 4. Obviously, one of the key parts of the operation in that case becomes a move from attribute protection (attr_accessible'/attr_protected’) to strong parameters. Doing so, I have actually struggled a great deal. And after a number of hours spent on reflecting on the whole ordeal I came to the conclusion that it was not entirely my fault, and not even a problem with how the previous state of the application was when the migration had to be done.
The problem is strong_parameters itself. See, when you design an API, you usually assume a number of use cases, and then streamline the workflow for those specific use cases to the best of your ability. When situations arise where your API does not perform satisfactorily, you basically have two choices:
- Press on and state that these situations are not covered by your API
- Re-engineer the API to accomodate the new requirements
When designing strong_parameters, the Rails gang apparently went for the first approach. Except that since stating that “you are on your own” is not often encouraged as a message to developers-customers, it has been pretty much been swept under the rug. As a result, strong_parameters have been released (and codified as The solution to input validation) without (in my opinion) due thought process.
Since I was finally able to wrestle through it, behind all the frustrations I could actually see why strong_parameters did not work. It did not work because it is a badly designed API. And I would like to take some time to walk through it, in hopes that it can reveal what could have been done better, differently, or maybe even not at all.
So, let’s run through it.
It is both a Builder and a Gatekeeper
By far the biggest issue with the API is this. It is both something we Rubyists tend to call a builder, and something we tend to call a gatekeeper - this is more of my personal moniker. Let’s explain these two roles:
- A Builder allows you to construct an arbitrarily-nested expression tree that is going to be used to perform some operation.
- A Gatekeeper performs checks on values and creates early (and clear) failures when the input does not satisfy a condition.
For example, Arel is a good citizen of the Builders camp. A basic Arel operation is strictly separated into two phases - building the SQL expression out of chainable calls and converting the expression into raw SQL, or into a prepared query. Observe:
where(age: 19).where(gender: 'M').where(paying: true).to_sql
You can immediately see that the buildout part of the expression (the where() calls) and the execution (to_sql) are separated. The to_sql call is the last one in the chain, and we know that it won’t get materialized before we have specified all the various conditions that the SQL statement has to contain. We can also let other methods collaborate on the creation of the SQL statement by chaining onto our last call and grabbing the return value of the chain.
XML Builder is another old friend from the Builders camp, probably the oldest of the pack. Here we can see the same pattern
b.payload do
b.age 18
b.name 'John Doe'
b.bio 'Born and raised in Tennessee'
end
b._target # Returns the output
The obtaining of the result (the output of the Builder) is a definitely separate operation from the calls to the Builder proper. Even though calls to the Builder might have side effects when it outputs at-call-time, we know that it is not going to terminate early because the output object it uses is orthogonal to the Builder itself.
Strong parameters violate this convention brutally. The guides specify that you have to do this:
parameters.permit(:operation, :user => [:age, :name])
If you have strict strong parameters enabled - and this is the recommended approach since otherwise parameters you did not specify will simply get silently ditched - if you have even one single key besides :operation and :user at the top level, you will get an exception. If you supply a parameter that is not expected within :user - the same. The raise will occur at the very first call to permit or require. This means that the “Gatekeeper” function of strong_parameters is happening within the Builder function, and you do not really know where the Builder part will be aborted and the Gatekeeper part will take over.
Since we are so dead-set on validating the input outright, at the earliest possible opportunity, this mandates an API where you have to cram all of your permitted parameters into one method call. This produces monstrosities like thos:
params.require(:user).permit(
:email,
:password,
:password_confirm,
:full_name,
:remember_me,
:profile_image_setting,
{
paid_subscription_attributes: [
{company_information_attributes: [:name, :street_and_number, :city, :zipcode, :country_code, :vat_number]},
:terms_of_service,
:coupon_code
]
}
)
Those monstrosities are necessary because applications designed with use of nested attributes, and especially applications designed along the Rails Way of pre-rendered forms, will have complicated forms with nested values. And those forms are very hard to change, because they are usually surrounded by a whole mountain of hard-won CSS full of hacks, and have a very complex HTML structure to ensure they layout properly.
In practice, if we were to take the call above and “transform” it so that it becomes digestible, we would like to first specify all the various restrictions on the parameters, and then check for whether the input satisfies our constraint - divorce the “Builder” from the “Gatekeeper”. For instance, like this:
user_params = params.require(:user)
user_params.permit(:email, :password, :password_confirm, :full_name, :remember_me, :profile_image_setting)
paid_subscription_params = user_params.within(:paid_subscription_attributes)
paid_subscription_params.permit(:terms_of_service, :coupon_code, :company_information_attributes)
company_params = paid_subscription_attributes.within(:company_information_attributes)
company_params.permit(:name, :street_and_number, :city, :zipcode, :country_code, :vat_number)
user_params.to_permitted_hash # The actual checks will run here
This way, if we do have a complex parameter structure, we can chain the calls to permit various attributes and do not have to cram al of them into one call.
On a small team, not being dicks sometimes trumps efficiency
There is an inherent difficulty to maintaining velocity. We always want things more streamlined, more efficient, more lean - sky is the limit, really, if the technical realm of a product is not micromanaged by the higher echelons of the company management, but is upgraded by grassroots effort. A good team of engineers worth their salt will, as wel know, improve and clean the product of must of technical debt - all a good manager has to do, really, is not to impede that process.
There is an inherent difficulty to maintaining velocity. We always want things more streamlined, more efficient, more lean - sky is the limit, really, if the technical realm of a product is not micromanaged by the higher echelons of the company management, but is upgraded by grassroots effort. A good team of engineers worth their salt will, as wel know, improve and clean the product of must of technical debt - all a good manager has to do, really, is not to impede that process.
There is an inherent concern however, which becomes especially important when the teams are small. Sometimes, velocity and efficiency need to be sacrificed a little if the team wants to preserve equilibrium in human relationships.
The sad state of human arrogance today
Lately an article has been making rounds on HackerNews where eevee laments on his tribulations when installing Discourse.
I’ve read it cover to cover, and I must admit it did strike a few notes with me, especially because I write Ruby web apps for a good decade now, with Rails and without. Most of the points named in this article are valid to some extent, but I profoundly disagree with the overall tone and the message.
First let’s look at the narrative:
- Ruby is not a primary language eevee is faimilar with (he’s primarily a Python/Rust guy from what I could see - because I have been reading his other articles just a few days prior).
- He does not have a lot of experience deploying a modern Ruby stack in production for web apps
- Through his experience with Python he probably misses the fact that the Python deployment story is probably just as painful as Ruby’s at this point. Moreover, some horrible relics of Ruby packaging (gemsets) still exist at large in the Python world (virtualenv).
- He picked a project which is explicitly pushing the envelope in it’s usage of fancy tools, and thus indeed wants to have it’s mother and the kitchen sink for dependencies. This is not because you need fancy tools, but because for a modern web app you do need search, you do need a job queue, you do need push messaging.
- Exactly because the developers of Discourse (whom I admire greatly) realise that the dependency story in Discourse is effin hard they suggest, loudly and clearly, to deploy it via images or containers. Eevee chose to use neither of these approaches, but facing the consequences of this decision proved to be a world of pain (exactly as predicted).
- He has a complex Linux configuration, which to me (from my uneducated perspective at least) looks like a Linux build that has been accrued over the years with all sorts of manual tweaks (90% of them probably having to do with X11 and sound of course), and migrated over and over - as a result of which you indeed end up with a 32 bit runtime on top of a 64 bit kernel. This, for tools that assume a default configuration for most of situations, is a recipe for butthurt.
- He also had to use a PostgreSQL extension, which does not ship as a default part of the package.
Instead of raising my hands in violent agreement with him, or rebutting his post point by point, I would like to look at the actual reasons why this stuff happens.
Quitting VFX, one year on
So that might be a surprize to some people reading this – if someone still reads this blog at all. But around Christmas 2013 I have decided that I had enough. Enough of the being pleasant. Enough of the wonderful Aeron chairs and enough of the Flame. I was just sick to my stomach.
Throughout my life I have been one of those blessed few who never had to work at a place they hated. An essential benchmark of the quality of life for me is that I wake up in the morning and feel like going to work. When that feeling is gone, and the fact of going to work becomes dreadful instead – that is the clearest indicator for me that it is time to move on.
This in fact turns a major page in my life. I have dedicated 9 years of it to the Flame, just
like I wanted to. I have seen the demise of the SGI Tezros (I will forever
remember what $hinv stands for and what the Vulcan Death Grip is). I have done some great
compositing work, from set extensions to beauty to morphing. I have worked with some of the greatest,
most wonderful art directors in Amsterdam – it did turn out that most of them have grey hair, a beard,
a belly and an impeccable sense of humor - and, first and foremost, artistic vision.
I worked at an amazing company which gave me so much I will be forever grateful. Of course there were ups and downs, but I was incredibly lucky when I stumbled into it by accident in my search for an internship.
I have enjoyed some very interesting projects, mastered Shake and Nuke, became one of the best matchmovers in town. Have beta-tested new versions of Flame and had the pleasure of meeting the wonderful, predominantly-Francophone team of it’s makers. I’ve met a mentor who transformed me from a rookie into a good all-around Flame op. I got pretty much everything I wanted.
For a month I even lived at the office, when the situation with my landlady became unbearable. I worked my year as the night shift Flame operator - so that chevron is earned too.
The logical next step would be London. The problem with that is - I was not prepared to dump my residence status in the EU just for the privilege of working on the next fab rendition of Transformers IX. You see, most people in Western countries are equal, but people with less fortunate passports are somewhat less equal than others. So if I were to move on to the UK it would mean a new alien status, a new residence permit, a new work permit, and all the other pleasures such moves entail.
Also I got tired of client work and all of it’s facets that tend to drive you to exhaustion. It was extremely challenging and very rewarding for me - especially me being an overall introvert that I always was - but at a certain point I’ve started losing the grip. The guy that once was Julik started to become some other person. Some other person that I didn’t like seeing in the mirror when I brushed my teeth. Some person that had to develop reactions to the outside stimuli that I did not condone. In short - the beautiful honeypot I was so eager to devour started to consume me.
So after having dedicated 9 years to visual effects and Flame, it was time to turn the page. Since I was developing pretty much all those 10 years (I started about a year prior to this blog being first put online) becoming a Ruby developer seemed par for the course. I love programming, I love Ruby, and I’ve made some great stuff using it. Tracksperanto has become the de-facto go-to piece of kit for many, and even though I never got code contributions for it – most of the post bunch speaks Python only – I was able to maintain it with excellent longevity and it saved many a matchmove project, both for myself and for many others.
Work/life balance
This has more to do with company culture, but in the past years I’ve learned that when you process yourself into a skewed work/life balance you have to understand the benefits and the costs. Essentially, when doing all-nighters, participating in sprints, crunch times, enabling your mobile phone at night - think very well what you are giving up, who benefits from it and whether the compensation is adequate. Overtime is not free - you are paying for it with your health, with your family life, with your friendships and love and care and affection. Being on call is not free.
You absolutely should do it when doing the work you love - but consider whether what you are getting for it. When in doubt, re-read Loyalty and Layoffs.
The game here is detecting when the overages and pressures stop being of benefit to you, and only stay beneficial to your employer or client. It is an extremely fine line, and most good managers are good at masking it from view. It took me a full 15 years of working in different roles to get the feeling for when enough is enough, and even at that I had to switch careers to restore the balance.
Don’t think that development is foreign to crunchtime (read some jwz if in doubt) but it is highly likely that you will be confronted with it sooner in a VFX career. Remember - how much of it you will take, and what for - is your decision. Nobody - not your employer, not your manager, not your parents - are responsible for the decisions you make about it.
Matchmover tip: obtaining the actual field of view for any lens using a survey solve
The best camera is the one that’s with you Henri Cartier-Bresson
For a long time we have used a great technique at HecticElectric for computing the lens field of view (FOV) values. When you go to film something, you usually record the millimeter values of the focal length of the lenses you use (or “whereabouts” if using zooms instead of primes). This approach, however, is prone to error - because 3D software thinks in terms of abstract field of view angle, not in terms of the combination of the particular focal length + particular sensor/film size.
So we devised a scheme to reliably compute the field of view from shots of specifically chosen and prepped objects, that we call shoeboxes. This yields very accurate FOV values for any lens (including zooms at specific settings) and can be used with any camera/lens combination, including an iPhone.
Building Nuke plugins on macOS, Christmas 2014 edition
Building Nuke plugins on the Mac, Christmas 2014 edition
As 2014 is folding to a fanfare close, we here at julik live would like to take you, dear reader, to 2009. To recap what happened in 2009:
- The Icelandic government and banking system collapse
- Albania and Croatia are admitted to the North Atlantic Treaty Organization (NATO).
- The Treaty of Lisbon comes into force.
- Large Hadron Collider gets reactivated.
- Apple Computer Inc. releases OSX 10.6 Snow Leopard
That last fact is of uttermost importance for us. We are going to time-travel to 2009 to see how life is like in a world where everybody uses systems so old they cannot be obtained legally. To the world of high-end VFX software.
See, I made a Nuke plugin back in the day. Because I really wanted to and I needed it. As faith would have it, I also really wanted to share it because it could be useful for many other VFX artists using SynthEyes – which I still consider the greatest, fastest and the most affordable 3D tracking package ever.
However that plugin development thing puts me way out of my comfort zone. See, this is C++ we are talking about - but if only. We are also smack in the middle of the DLL hell because, as you might imagine, a plugin for someone else’s software is a DLL that you have to build (or a .dylib, or a .so - a shared library for short). Now, 5 years have passed and I somehow managed to maintain a build pipeline for the plugins intact - for quite a long while for example I specifically delayed upgrading from 10.5 just to avoid everything that is related to this dependency hell. Dependency hell in the world of building shared libraries for closed-source hosts is defined as:
- you have to build against system library versions that have the same ABI and same versions
- you have to build with exactly the same compiler
- you have to build against system headers that match the libraries
- you have to build with non-system libraries that match the system libraries. Fancy some boost perhaps? Or some fancy OpenEXR library? Or some image compression libraries? If you do, we need to talk. Trust me, afte going through this ordeal a few times you will reconsider their use and appreciate the zen of doing without.
- you (mostly) have to build with non-system libraries that match the versions used by your host application
That leads to an interesting development cycle. At the beginning of that process, if you are lucky and starting early, you will have a machine that carries somewhat-matching dependency versions for all of the above (or the dependency versions are obtainable). At the beginning you will invariably struggle with obtaining and installing all that stuff since it by definition is going to be obsolete already, but that is mostly manageable. I remember that I didn’t have to install anything special back when I was building on 10.5 at the beginning of SyLens’ lifetime.
On the benefits of laptop stands
When you look at pictures from trendy startup offices you often see laptop riser stands.
One might think that you would do that to make your desk look neater. Or that it is for better posture. Or just to have yet another neat Apple-y looking apparatus in your vicinity for more hipster look. However, there is a benefit to laptop riser stands that some do not quite see upfront.
However, there’s more to it than meets the eye.
Checking the real HTTP headers with curl
curl, the seminal swiss army knife of HTTP requests, is quite good at many things. Practically everybody knows that you can show headers using the -I flag:
$curl -I http://example.com/req
However, this is plain wrong in a subtle way. See, I sends a HEAD
request, which is sometimes used to probe the server for the last
modification date and such. However, most of the time you want to check
a real GET as opposed to a HEAD. Also, not all web frameworks will automatically implement a HEAD responder for you in addition to a GET responder. It’s also downright misleading because with quite a few proxies the headers you are going to be getting from the server will be different for a GET as opposed to a HEAD.
To perform a “real” GET, hit curl with a lowercase i as opposed to upprecase.
$curl -i http://logik-matchbook.org/shader/Colourmatrix.png
However, this will pollute your terminal with horrible binary-encoded strings (which is normal for a PNG after all)… There are ways to do a full GET and only show a header, the easiest being doing this:
$curl -s -D - http://logik-matchbook.org/shader/Colourmatrix.png -o /dev/null
Works a treat but is long and not memorizable. I put it in my .profile as headercheck:
alias headercheck='curl -s -D - $1 -o /dev/null'
So anytime you want to check headers with a real GET request, hit:
$headercheck http://url.that/you-want-to-check
and you are off to the races.
Tracksperanto is fully Ruby 2.0 ready
Just added Ruby 2.0.0 to Tracksperanto’s Travis config and the results are in. Our compatibility matrix now looks like this:
So now we also happily run 2.0.0 in addition to 1.8.7 and 1.9.x. Feels nice to stay compatible and current at the same time.
This also means that likely most of the Tracksperanto dependencies are also compatible with 2.0.0.
Checklist for custom form controls in your web app
Recently I had a privilege of reviewing a web app that is directly relevant to my work field. It is in fact an iteration on the system we are actively using at the company. After having a poke here and there, I was surprised to find that the custom controls epidemic was not over for some people.
All popup menus on the system (all select elements) were implemented as custom HTML controls with custom event handling. I hate this kind of thing not because it doesn’t look like a native control - this is in fact secondary. Most of the apps I use daily (Flame, Smoke, Syntheyes, Nuke) do not use the native UI controls at all.
What I hate is a substantial reduction in useful behavior compared to a native control. There is a load of stuff humanity has put into menu implementations for the past 40 years. Every custom select implementation is bound to be reinventing the wheel, in a bad way.
Imagine you are all giggly and want to make a custom select element - a menu. Or your boss does not get UX and lives in the art-directorial LSD fuckfest of the late nineties, and absolutely requires a custom control. Alright then, roll up your sleeves.
Running .command files on OSX in other interpreters than `sh`
We all know that on OSX you can create so-called .command files. In a nutshell, they are renamed shell scripts.
When you make them executable and double-click them, they will run by themselves within Terminal.app.
A little less known fact about them is that you can actually script them in any language of your choosing. For the reasons of distribution it’s better to stick to the versions of things available on OS X by default, obviously. You do this by modifying the shebang, just like you would for any other shell script.
For example, a .command file that runs via Ruby would look like this:
#!/usr/bin/ruby
puts "Hello from #{RUBY_VERSION}"
Note that I am not using /urs/bin/env here to get at the right version of Ruby since that turned out to play up on 10.6 somehow. I stick to the system ruby instead.
Gracefully handling NFS mounts on OSX laptops
For the last few years, all the work I do has been equally split between Flame systems running on Linux and a couple of Macbook Pro’s running OSX. At Hectic we make use of NFS to make the same servers available to all of our client workstations which are an equal mix between Linux and Windows (Macs do not ouse our NFS facilities much). One of the problems I have encountered has been configuring the NFS mounts on my laptops for graceful timeout.
Now, in the ideal world NFS is designed to handle unmounts gracefully of course. That is, the client is supposed to suspend or fail on IO operations when the requisite mount
is not found. Apple, however, in it’s infinite wisdom, designed a slightly different system for it’s OSX Server infrastructure. The mounts that you were used to designate in the Directory Services application or, more recently, in Disk Utility (explained in tutorials like this one are
managed by automountd, Apple’s daemon controlling the directory mounts. This is the daemon that originally was designed to provide automounted user home directories and other
handy things in the /Network folder on the root drive. In Mountain Lion this feature has been removed, but people try to use automountd nevertheless, explained in a post here.
However, automountd has been designed for limited applications - like computer labs at colleges and universities. It is not capable of detecting offline servers or stale mounts, and even with all the settings tweaked it will never timeout on an NFS mount. In practice, this means that if I have some NFS mounts defined on my laptop and I take the laptop
somewhere where the NFS servers cannot be reached, the following will happen:
- All navigation services dialogs in all applications will beachball when trying to access the stale mounts
- All applications having documents open off of these servers will beachball
- Due to Lion and Mountain Lion’s automatic document reopening of last-used documents per application apps that support this feature will beachball again on startup.
This is not pretty. What you actually want is a nice dialog like this:
when the mounts are gone and then to be able to proceed with your business.
And this turned out to be remarkably simple to achieve. The easy solution is - do not use automountd at all, but mount manually. I do it with a Ruby script that I need to run in the morning once my laptop is up and running on the company network. When I come home, the OS falls back to the natural behavior
of simply unmounting the stale shares instead of having automountd hammer on them indefinitely.
Messages versus slots - two OOP paradigms
I’ve had this discussion with Oleg before, but this still keeps coming up again and again. See, alot of people are pissed at Ruby that you cannot do this
something = lambda do
# execute things
end
something() # won't work
and also cannot do this
meth = some_object.method(:length)
meth(with_argument) # call the meth
However this comes from the fact that Ruby is a message-passing language as opposed to a slot language. What I tend to call a slot language is something that assumes objects are nothing more than glorified hash tables. The keys then become either instance variables or, if they store a function, “callables” (the way Python calls it).
So you might have an object Car that has:
[ Car ] -> [weight, price, drive()]
all on the same level of the namespace. Languages that operate on the “slots” paradigm usually have the following properties:
- It is very easy to rebind a method to another object - just copy the value of the slot
- You can iterate over both ivars and methods in the same flow
- Encapsulation is a decoration since everything in fact still is in the same table
- You can call variables directly since local namespace is also a glorified hashmap with keys for variable names and concent that iscallable.
Due to various reasons I dislike this approach. First of all, I tend to look at objects as actors that receive messages. That is, the number of internal variables stored within an object should not be visible from the outside, at least not in a formal way. Imagine a way to figure out the length of a string in a slot language.
str.len # is it a magic variable?
str.len() # is it a method?
# or do we need a shitty workaround which wil call some kind of __length__?
len(str) # WTF does that do??
There is ambiguity whether the value is callable or not, and this ambiguity cannot be resolved automatically because this expression is not specific in a slot language:
# will it be a function ref?
# or will it be the length itself?
m = str.len
and therefore languages like Python will require explicit calling all the time. This might be entering parens, or doing
m.do_stuff.call()
Most OOP (or semi-OOP) systems known to us in the classic sence (even CLOS as far as I know) are slot systems - IO, Python, Javascript are all slot-based. This gives one substantial advantage: not having to specify that you want to move a block of code as a value explicitly. So you can do, for example in JS
// boom! we transplanted a method
someVar.smartMethod = another.otherMethod;
All of the rest are actually inelegant kludges. First of all, since a method can be used like a value for moving code from place to place, you always need explicit calling. Second, your slots in the object do not distinguish between values and methods so you have to additionally question every value in the slot table whether it is a method or a variable. Also, in slot languages you need to specify that an instance variable is private or not (since normally everything is in one big hashtable anyway).
On the other side we have message-passing languages, like Smalltalk and Ruby. In there anything you retrieve from an object passes through a method call whether you want it or not, because there are two namespaces - one for ivars and the other for methods.
You know that ivars from the outside of the objects are off-limits, and you know that everything exposed to the outside world iscallable, by definition. You also get the following benefits:
- everything only ever goes through getters and setters, so you just don’t have to think about them all the time
- you tend to avoid using objects as glorified hashmaps
- you get alot of smart syntax shortcuts
- refactoring a property into a getter/setter pair is a non-issue to the consumer code
Message-passing languages also adhere to the UAP.
When implementing your next programming language, first make it a message-passing system, and if you need performance improvements make internal opaque shortcuts to bypass the getter/setter infrastructure when direct properties are accessed. You will spare alot of people alot of useless guessing and typing.
Sequencing AJAX requests on "send-last basis"
So imagine you have this autocomplete thingo. Or a dynamic search field. Anything that updates something via AJAX when it’s value changes.
Now, it’s tempting to do this (I am speaking prototype.js here, jQuery would be approximately the same.
function updateResults(field) {
new Ajax.Request('/s', {
method:'get',
parameters: {"term": field.value},
onSuccess: function(transport){
var archiveList = transport.responseText.evalJSON();
displayResults(archiveList); // This updated the DOM
}
});
}
new Form.Element.Observer(searchField, 0.3, function(form, value){
updateResults(form);
});
However, we got a problem here. Imagine that the user types something, and the observer fires when the field contains
some. Now, logically some would find more entries than something and probably the search (the request) will take longer. So if you visualise the call timeline here’s what you will see (pardon my ASCII):
| | ^ ^ GET /s?term=so | | Update DOM for "so" | GET /s?term=some Update DOM for "some" | | |===========================| | | | |=====================================================================|
So the more specific request will complete faster and will update the DOM first. However, after some seconds when the previous request completes the previous request will overwrite the DOM again with less specific results.
What you need to do to prevent that is to discard the requests that have been sent before the last one. To do this, use a recorded sequence number for the request per window, and discard the results that come too late. Of course this will not stop the client from pounding on the server (ultimately you will need clever tricks like caching responses, increasing observe intervals and such) but it will at least ensure that the user is looking at the most specific result.
function updateResults(field) {
// First init our counter
if (!window._reqSeq) window._reqSeq = 0;
// Increment request counter
window._reqSeq +=1;
// Store the sequence number of this request
var thisRequestOrderNo = window._reqSeq;
new Ajax.Request('/s', {
method:'get',
parameters: {"term": field.value},
onCreate: showSpinner,
onSuccess: function(transport){
// ...and if this request is not the last one sent
// discard it's payload.
if(thisRequestOrderNo < window._reqSeq) {
console.debug("Request was stale, skipping");
return;
}
var archiveList = transport.responseText.evalJSON();
updateDocument(archiveList);
},
});
}
This works since now the callgraph will look like this:
| | ^ GET /s?term=so | | | GET /s?term=some Update DOM for "some" | |=============(seq:3)=======| X | onSuccess returns early |==================================(seq:2)=============================|
Hat tip to Orbling for his SO answer on this.
Matchmover tip: making use of EXIF comments to know your field of view
So you got this batch of reference photos and just into doing some image - based modeling. Awesome! Except that you vaguely remember that there was a zoom lens used on the photo camera. So you’d say “not possible” right?
Nothing further from the truth! Canons actually have these smart lenses that report their current focal length to the camera, and this is something you can use to your advantage. Just like these super-expensive films do with their Cooke/i lenses but you never will since your production couldn’t afford them ;-) So, the magic.
Step one, load the pics into some software with decent EXIF support (like Lightroom or iView). Note the lens values and the camera model:
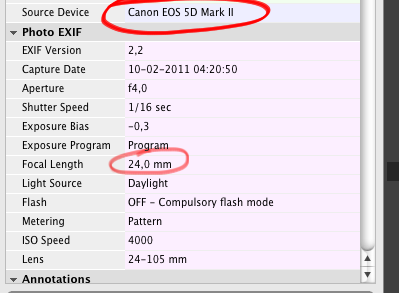
Step two, snoop the internets for sensor sizes:

Step three, enter film back data into your matchmoving software so that it knows how to properly compute FOV from the focal length
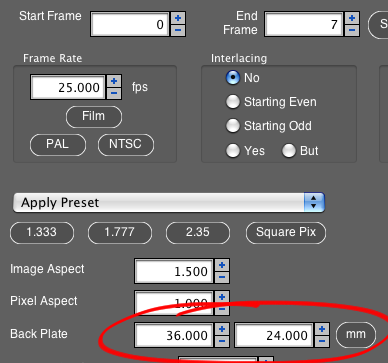
Step four punch in the lens millimeters.
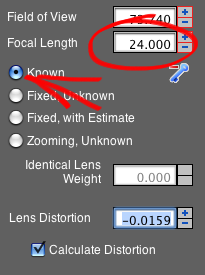
Step five - profit!
Tracing a Ruby IO object for reads
So Tracksperanto has a progress bar. Actually both the commandline and the web version have one, which helps to improve the user experience a great deal (some files uploaded on the site were converting for more than a few minutes). However, we need to display this progress bar somehow and to do it we need to quantify the progress made.
For exporting this has been simple.
tracker_weight_in_percent = trackers.length / 50.0
trackers.each_with_index do | t, i |
export_tracker(t)
report_progress( (i + 1) * tracker_weight_in_percent )
end
However, for importing stuff the pattern is not so evident. Most parsers in Tracksperanto work like this:
p = Parser.new
trackers = p.parse(file_handle_or_io)
It’s completely opaque for the caller how the Parser can quantify it’s work and report on it. Parsers do send status messages that we can use for status line of the progress bar, but no percentages (they also mostly consider the IO unquantifiable and just read it until it eof?s. Also, there are many parsers and introducing quantification into each one of them would be kinda sucky.
So I looked for a different approach. And then an idea came to me: we are reading an IO (every parser does). Parsers mostly progress linearly, that is - they make trackers as they go along the IO (with a few exceptions), so the offset at which the IO is can be a good quantifier of where the import is. What if we feed the parsers an IO handle that can report on itself?
Outputting overscan action scenes with 3D cameras
When you do set extensions, and especially when you use tracked cameras, it is often necessary to do 2-d transformations outside of your original frame. The most common thing to do is zoom out on your original footage, revealing your set extension. For this, you basically need two images, with one image being bigger and with both of them perfectly aligned, pixel to pixel. Of course you can manually scale the bigger image to match, but instead you can use a little of Flame math to do it precisely.
Just adjusting the size of your setup does not work as you would expect to - it does not increase the field of view of your camera, but instead changes the output resolution. When you want to output a background that will align with our original picture and yet contain overscan you need to know how much overscan to apply in terms of the camera FOV.
Update: In Flame 2011 and up you can just use the “Camera FBX” node and tweak the settings of the film back. Below the recipe for Flame up to 2011.
Architecture behind tracksperanto-web
So it’s been quite a while since tracksperanto-web went production, with more than 300 files converted so far with great results. I hope some sleepless nights for matchmovers worldwide have already been preserved and nothing could be better.
I would like to bring a little breakdown on how Tracksperanto on the web is put together (interesting case for background processing). The problem with this kind of applications (converters to be specific) is that the operation to convert something might take quite some time. To mitigate that, I decided to write the web UI for Tracksperanto in such a way that it would not be blocking for processing, so extensive use of multitasking is made.
Basically, the workers on the web app are fork-and-forget.
Very simple - the worker gets spun off directly from the main application, it writes it’s status into Redis and at the end of the job to the database. Tracksperanto jobs use alot of processor time and alot of memory, and with Ruby nobody can guarantee that jobs won’t leak memory. fork() is tops here since after the job has been completed the forked worker will just die off, releasing any memory that has been consumed in the process.
When processing is taking place, the worker process writes the status into redis which is perfect for this kind of a message bus application. Tracksperanto is designed so that every component can report it’s own status and a simple progress bar can be constructed to display the current state. So basically we constantly (many times per second) write a status of the job into memcached - percent complete and the last status message. To let the user see how processing is going, I’ve made an action in Sinatra that quickly polls memcached for the status and returns it to the polling Javascript as a JSON hash.
This scheme has the following benefits:
- Status reporting does not load the database (not needed and the information is hardly crucial).
- Zero memory leakage
- No Ruby daemon processes
- Start/stop control is tied into the webserver.
Note: lots of stuff removed from this post since it’s no longer relevant.
Announcing tracksperanto, a 2D tracking converter
I’ve released Tracksperanto, a small app that can convert 2D tracking data between many apps. In my work I often have to do 2D tracking and then transition to camera solves - some apps do it better, some apps do it worse and you seldom know which solver will give you a better result. I’ve taken a look at Mincho Marinov’s Survey Solver converter but found it inadequate (bloated code that is not easy to extend, only runs from within Maya and MEL is not the best language to process text). So I’ve written my own system to accomplish just that and released it as open source.
Stop the red tape before it gets any further
The industry is in an interesting state now. As VFX get more adoption across all disciplines of filmmaking, there’s more and more demand for our work ad at the same time things get devalued. There is much less experimentation (except at the top-notch facilities like ILM and DD), much less exploration - but the amount of work is actually increasing. Everybody seems to want more, faster and better than before, for less money. Good facilities are closing, not able to sustain their own weight in the economic downturn. However, there is one thing that still strikes me, after having worked in the industry for the past 3 years.
The red tape.
When I come to have a problem in the Ruby world, with some web technology or anything of that nature - it’s usually a matter of hours to get to a canned answer on one or other blog, wiki or forum. Asking people helps, and there is a “show source” making things even more accessible. There are whole universes where raw knowledge in the form of code roams free, ready to be taken. There is a thriving community of people sharing ideas, giving keynotes and presentations, putting these online for free. Every motion spurs discussion and natural, community QA. And there are open source projects, where you can examine the solutions to problems you face daily in their entirety - to learn and assimilate has never been so easy. It’s a thriving, lively ecosystem.
By comparison, the post/VFX business is a swamp. I’ll make use of my lowly position to say it out loud. Blogging post people are few and far between. And even when they do post, there is this uncanny feeling of “saying without saying”, the pressure that is mounted behind. As artists. we literally abstain from our own process, preserving the only right we might have left for ourselves - to put the work done on showreels for viewing to “audiences of close friends”. I talked to a very talented Danish animator once, and he told me that it’s usually around a year for a studio to give you even that - that meager playblast you have done for their show, contributing your sould, blood and sweat.
`_path` routes considered harmful
There’s been some talks lately on relative versus absolute routes and where they should be used.
Personally, I consider the point moot. If you have such a powerful tool at your disposal (Rails) there is one thing you certainly should do, once and for all - make all URLs both absolute and canonical. Here is the reasoning for that:
- Canonical URLs work in standalone documents (like PDF and downloaded pages). Anywhere you transition from displayable HTML to something else, you have to go canonical
- Atom and RSS feeds are busted when you use relative URLs. Granted, there is the xml:base but some feed readers just don’t give a shit (making all your links dead). Nothing is more frustrating than having unclickable links. NetNewsWire, last time I checked, did not honor
xml:base. This situation obliges you to rewrite all URLs that go out to feeds - The same for sent email - there is no mechanism for specifying a URL base for hyperlinks in mail messages.
Also, if you promote web service consumption off your app (REST or otherwise) you oblige the consumer to do path-munging for every redirect, every cross-reference and every parse just to drill down your site structure (all these ugly url.path = something things come from that).
So if you ask me, I’d just hardwire *_path to raise or play through to *_url. These are processor cycles (and wire bytes) well spent, because they simplify the consumption of your website outside of anything except the browser, and free you from deciding every time which one you need. Additionally, modern times never cease to amaze us with regards to ways our content can bleed out of the browser.
At some point I had to write a plugin to enforce canoncal/absolute URLs in text segments, and for Inkpot (the engine running this site) I use canonical URLs for the absolute most of the links and cross-references. The exception is the stuff going through the Camping router, but my gut feeling tells me that the use of Camping will be abolished here anyway.
Just my 2 cents.
The culture ain't it
So let’s imagine we want to run a CI server. And we want it to work with both githubs and gits and subversions and pwn everything. We skip CruiseControl.rb (after all it’s not awares of githubs right?) and decide to try out the new kid on the block. First of all, we immediately find out that:
gem sources -a http://gems.github.com
sudo gem install foca-integrity
Which in realistic parlance means there is no official gem, no official Rubyforge project - who hell needs Rubyforge now? Ok, on to business.
After 10 minutes of chugging, my Quad G5 finally manages to install all the 33 (it’s not a joke! 33) gems (of course they contain all the latest versions of datamapper and do-boo and do-foo and supermodular and whatnot - because you know, who the hell needs ActiveRecord anymore? we all do new modern stuff right? get out of the ghetto already!)
integrity install ~/integrity
The script complains that we do not have the right version of rspec. I mean, it’s ok that it did not pull it with the other 33 gems, might have been 34 - who cares? Of course there is no rspec-1.1.11 anywhere, because we’re on githubs and there are no official releases anymore. We’re all hippies and stuff.
integrity install ~/integrity
The script complains that it wants cucumber. Now this is downright insluting. Look, I do not need to have all the latest and greatest BDD megatools known to the universe to just run the application. I will never, ever need Cucumber I swear! Ok, let’s proceed.
Installing RDoc documentation for cucumber-0.1.16
/usr/local/lib/ruby/1.8/rdoc/parsers/parse_rb.rb:122:
[BUG] Segmentation fault
Now, this has nothing to do with integrity itself, but cmon - before making gems check that your docs build. I know rdoc is not stellar, and this is probably a bug in Ruby itself, but still - latest and greatest has it’s specificities.
Ok, swell. After bypassing rdoc with --no-rdoc option cucumber finally installs and we can install the app itself. Gee. But clearly, depending on the universe of bleeding-edge testing gems that are only on github is a massive FAIL. Excuse me but this is just so.
Now… the app says that to enable email notifications I need another gem from githubs. Y’know folks, probably 99 percent of people installing a CI server would want emails on broken builds, why I need a gem 35? Well, nevermind… another gem install.
Oh wait we also need thin (this is recommended). Another gem. Let’s get rolling. Just add the repo over here…
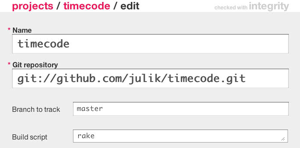
Wait a minute, this is for githubs and stuff - why should I copy the repo URL into the interface if it knows more about githubs than I would ever to know in my lifetime?
Anyways, let’s build.

Folks, these are really cool. Swell. Trust me. Besides, watching your fork queue on the same githubs might work well too.
Note: - I am not bashing on Datamapper specifically, I’m sure it’s got it’s pros and cons and I sure know that it has a migration engine. However, when you transform your source control into your download site you better know what you are doing and which state your build has.
To put the final note to the piece, we proxy our external server to my box where Integrity is running (just to try out the setup). 503 Service Unavailable
review:~ julik$ curl http://xx.xx.xx.xx:8910/
curl: (7) couldn't connect to host
So the default install is not routable from the outside (either due to port number being too high or to the defaults of thin). If there were an art to choosing bad defaults - this is a masterpiece.
Here ends my adventure with Integrity. I’m off to figure out how to uninstall all this crap that found it’s way onto my system for this entertaining user experience moment.
P.S. Just for comparison, on the same machine:
review:tmp julik$ git clone git://github.com/thoughtworks/cruisecontrol.rb.git
Initialized empty Git repository in /private/tmp/cruisecontrol.rb/.git/
remote: Counting objects: 8917, done.
remote: Compressing objects: 100% (3598/3598), done.
remote: Total 8917 (delta 5090), reused 8688 (delta 4940)
Receiving objects: 100% (8917/8917), 9.97 MiB | 26 KiB/s, done.
Resolving deltas: 100% (5090/5090), done.
review:tmp julik$ cd cruisecontrol.rb/
review:cruisecontrol.rb julik$ rake
318 tests, 765 assertions, 0 failures, 0 errors
39 tests, 174 assertions, 0 failures, 0 errors
22 tests, 43 assertions, 0 failures, 0 errors
Here’s the same done right.
Nemacs, nevim
Had a discussion recently with Yaroslav on switching to Emacs or vi. And I tried again and I failed. The reason is so stupidly obvious it’s hard to explain. You see, I got this:
This is not a cultural thing. I need to switch my keyboard layout, hundreds of times a day. And the Cmd+Space combo is the most worn one on my keyboard, by far.
EDL Ruby module hits the streets
As promised in an earlier entry, here comes the announcement for the EDL library for Ruby. It allows you to parse EDL files and examine their content in a relatively sane way. Example:
edl_part = '020 008C V C 08:04:24:24 08:04:25:19 01:00:25:22 01:00:26:17'
list = EDL::Parser.new(fps = 25).parse(edl_part)
# An EDL::List is just as any other Array
list[0].class # => EDL::Event
list[0].src_start_tc # => #<Timecode:08:04:24:24 (726624F@25.00)>
list[0].rec_length_with_transition # => 20
The documentation is complete now. The only dependency is the Timecode gem announced earlier. All of these tools (Depix, Timecode, ED…) are also moving to their own project on Rubforge. I hope that can be of use to people who agree with me that paying 170 bucks for a DPX renamer or a DPX conformer is insane in 2008.
I also have high hopes that libraries like these will help Ruby make way in the post industry, where Perl (and recently Python) reign supreme.
Some new Ruby libraries to boot
Hot on the heels of the recent graduation project activity I’ve released a few infrastructure libraries in Ruby that I use to manage the indie pipeline here. These are Depix, EDL and Timecode.
Timecode is a value class for SMPTE timecode information. It stores the framerate and the number of frames and supports all basic calculations (like addition, subtraction, multiplication and what have you), parsing and other manipulations that you will likely want to perform with a timecode field. It also plugs easily into ActiveRecord. Here’s how to scan a range of timecodes for example:
(Timecode.parse("10:00:00:00")..Timecode.parse("10:00:10:01")).each do | frame |
puts frame
end
Depix scans DPX file headers and makes them accessible as Ruby objects. There is some functionality for writing them back after editing but I would not recommend using it just yet. Here’s how to scan a whole directory of DPX files and sort them by time code (this relies on the Timecode gem as well):
dpx_files = Dir.glob("/RAID/NewScans/*.DPX").map do | dpx_path |
Depix.from_file(dpx_path)
end.sort{|dpx1, dpx2| dpx1.time_code <=> dpx2.time_code }
Depix supports the convention of reel name assigned to device.orientation field and it’s available as flame_reel on every DPX object read into memory. If you are courageous enough to write to DPX files with it you can even spare quite some bucks on tools like this one.
EDL is still in the making but can be tried out already (look at the API) - it can be used to analyze an EDL file. It even supports speed changes and SMPTE wipe inspection.
The goodies can be installed by doing
sudo gem install depix timecode edl
and all the tracking happens through my spankin’ new GitHub page
Come to think of it, these three can be combined to do some powerful and painless data-wrangling for file-based workflows. And you can also make your own CinemaTools-like apps.
Flame tricks: setup render prefixes
Here comes another Flame workflow tip. This one is used by colleagues of mine, but I found it very useful as well. One of the things that sometimes takes too much time is figuring out where has a clip come from. Your colleague has worked a project for a while, your library is full of clips and you are called in on a whim to fix something in presence of a client. Twenty minutes are spent looking for the setup that has produced a specific clip, and 10 minutes are all the fix takes. Sounds familiar? Here’s the recipe:
When making setups, start their names with module prefix. Like BA for Batch, AC for Action, MK for Modular Keyer and so on. When you render from Batch, assign the name of the output to be the same as the name of the setup. Action setups will render with the name of the setup already assigned to the rendered result. Including version (like V1, V2 and so on) in the setup is also helpful :-)
So, if you have shot 10, which is EDL event 10, call your Batch setup BA_Event0010. When you find a result called BA_Event0010, you will know to look for the Batch setup of the same name. AC_Event0020 will mean that you look in “action” directory for Action setup of the same name, and so forth.
Here some handy prefixes and suffixes:
- BA - Batch
- AC - Action
- MK - Modular Keyer (beware: not assigned automatically on render)
- _paint suffix - for AC_E001_paint will mean that this is an Action result with touch ups on top
- KEY - Keyer (also not assigned automatically)
Here some more that we don’t use (modules are rarely used)
- LA - Layered timeline (with Axis effects, BFX and so on)
- TW - Timewarped
- WR - Warper
- DIS - Distort
The lifted offset of the gained gamma
When you are told about the gamma, offset and gain, you can see it as the following Photoshop curve alterations:
For lift (or offset) this is the value that will be added to every input color:
For gain, this is the value that will be added to the absolute white of the channel and will decrease to zero as the input color goes to zero:
For gamma, this is the number that will be added to power to which the input value of the channel will be raised (this is totally unintuitive, so different software gives you different interpretation of the gamma input - but it does the same):
Effects of lift
Everything becomes darker or brighter.

Effects of gain
Brighter colors become darker or brighter - the brighter the color the stronger the difference, blacks stay the same.

Effects of gamma
The midtones become brighter or darker, the whites and blacks stay the same

Combined effect
Depends on the adjustments, of course. These adjustments:
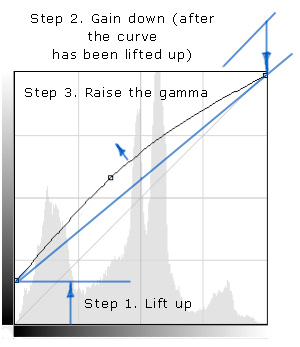
give the following result (uncorrected image left):

Why it’s useful to know
Now you know what these controls in the Flame will do, same for Combustion:

Most other color-correction plugins and apps usually assume this terminology (Apple Color, Colorista and all the others).
Flame tricks: transfer output
This one is just too good to be true, and few flame ops seem to use it.
Pull a clip into Batch, do something with it and prepare an output. See how unhandily the output is 100 frames while the input is only twenty? Also, the input clip has timecode attached to it, which is useful to have on the output clip as well.
But who likes to type? Hold down T (mnemonic for Transfer) and click the input node with the output node selected. The length, name and timecode are automatically adjusted to match. Moreover: see that handy little “Offset timecode” button on the left? It means: “if you render from frame 25, start the timecode of the result from 01:00:32:00, and not from 01:00:31:00”. It’s even turned on by default for you. Also the LUT is going to be enabled so that you automatically truncate your clip to 10 or 8 bit (if you are in a 12 bit project).
So much typing spared with one shortcut.
XMLRPC and Builder, a marriage made in heaven
This one is an example of why if you do XML you better do it right. I’ve written this blog with an aim for spotless MetaWeblog API support (I hate Web UI’s and I own both MarsEdit and Ecto licenses). I also don’t have an aversion to Dave Winer, and Atompub is not there yet IMO.
So I’ve implemented a small MetaWeblog responder based on Ruby’s XML-RPC module. The module is somewhat antiquated and the docs are not always telling all that you might need, but there is a little problem which is actually very serious - it uses a bozo XML writer.
Recently I’ve posted an entry about caches. When I’ve posted it and retreived it via MarsEdit, everything went well. But then an update to MarsEdit came along, and lo and behold - the updated MarsEdit was not able to retreive the very entry the old one has made.
Hmm… let’s see up close. I copied the XML response into a standalone XML document and ran it through xmllint.
Even more interesting. The character in question is ASCII 005, the ENQ character. Don’t know how MacOS X managed to type it into the entry box in MarsEdit, but it certainly was there!
![]()
This is an ASCII “control” non-printable character, and putting it into XML is anything but responsible. Even though it might be present in the blog entry itself, it should never bleed through into the XML representation for an RPC call! So I went out to investigate what writes XML for Ruby’s XML RPC. I wish I didn’t - to spare you a search, the file you need is create.rb.
Let’s put it that way - the only sanitization done is replacing the obligatory entities. The rest.. well the rest is expected to somehow happen when you pass your results to XML RPC. The XML writer in Ruby’s RPC works based on text concatenation.
Brutal fragment cache (with automatic transmission)
Recently I’ve hit that painful mark, y’know… A page on a Rails site I’ve been developing crossed the dreaded “1 second” request time. This can’t be happening, thought I - it’s just a list of objects! One SQL request, bonafide, no associations fetched, all indexes are in place… and the most aggravating was - the SQL request itself was a measly 0,1 seconds long.
Something is wrong. After a short investigation the problem turned out to be of the following nature:
<% @models_that_can_be_thumbnailed.each do | model | %>
<%= render_a_beautiful_thumbnail_with_other_widgets_for(model) %>
<% end %>
I’ve hit the “repeating render” (or “slow helpers”) problem - one of the most stupid Rails aggravations in the performance department. See tha’ slide about the app spending 30 percent of time in textilize? That’s about us. The beautiful thumbnail render entails not just doing ERB though - it’s doing captures, calculating a hashed URL via signed_params and doing a bunch of other stuff. Done 100 times in a row it was most enough to escalate a simple image listing into a performance disaster. So, caching to the rescue - and, more specifically, the Rails fragment cache. After all, I’ve taken care to render the thumbnails in most the same way almost everywhere (with the same recognizable widgets and sizes), but which ones - that varies per page, search result and so forth.
So, we read about the Rails caching. As it turns out, it recommends us to cache stuff by key, but… the key has to be a String! Or, more specifically, it can be a String or a hash of options (which most likely comes from url_for. So I’m encouraged to specify from which controller I am caching the fragment, from which action, and also it’s probably expected that I will introduce some value that will help me identify what exactly I am caching. Like a model primary key value, for instance.
<% @models_that_can_be_thumbnailed.each do | model | %>
<% cache :type => 'thumbnail', :model => model.class.to_s,
:lotso_other_things_that_can_vary... do %>
<%= render_a_beautiful_thumbnail_with_other_widgets_for(model) %>
<% end %>
<% end %>
Meh. Such a hassle. Let’s examine the problem here: I have an object (an Image model). I know that there were no changes to this Image as long as any of it’s attribute values did not change. There are no associations to track on it (this can vary, but still). As long as the Image stays the same, the thumbnail will be the same as well - and the cache fragment too! Why should I bother to pass the key of the Image to the cache key method if I know that the state of all the fields in the model can tell me about the freshness of the cache? But bear with me here. Let’s say we do this:
@users_images = User.images
We know that a @users_images variable also holds a certain state - it’s an Array with Image objects in it. If the images change, then @users_images will change too, right? It will just contain different objects.
So, let’s see again - we are actually not limited to some arbitary string key for an object’s cache key, we can use the object itself as state indicator. Tobi Lütke said that the most useful thing is to be specific on what you want to get from the cache. So a simple realisation dawned on me:
If we know what we want to cache and based on what the cache key can change, we can transform our objects themselves into cache keys.
Organized thread collisions
We don’t like when things collide.

Photo by szlea
But what if we need them to? What if we want to ensure that should a collision between threads happen, things will not go out of hand?
This is remarkably easy to do. Let’s pretend we want $somevar to be thread-safe:
require 'test/unit'
class Collision < Test::Unit::TestCase
def test_that_fails
a = Thread.new do
5.times do | t |
$somevar = true
sleep(rand(10)/200.0)
assert_equal true, $somevar,
"Somevar should keep the state true"
end
end
b = Thread.new do
5.times do | t |
$somevar = false
sleep(rand(10)/200.0)
assert_equal false, $somevar,
"Somevar should keep the state false"
end
end
ensure
a.join; b.join
end
end
Fail. Global variables are never thread-safe, neither are class variables and module attributes.
The .times call is somewhat cargo cult programming, because this fails for me on first iteration. Replace the $somevar with your getter and setter and you should see negative results immediately.
How does it work? Simple - we are spinning off two threads, they set the variable and wait in Kernel#sleep for the other thread to arrive and do it’s own assignment. It ensures that between the variable assignment and the assertion there’s just enough time for another thread to set the new value for the variable.